IO 简介 操作系统分为两种 I/O:
网络 IO: 本质是 socket 读取
磁盘 IO: DMA 操作读取
I/O 过程
DMA(Direct Memory Access, 直接存储器访问) 将数据从磁盘文件先加载至内核内存空间(缓冲区), 等待数据准备完成, 时间较长
CPU(Central Processing Unit, 中央处理器) 将数据从内核缓冲区复制到用户空间的进程的内存中, 时间较短
I/O 模型 同步/异步 (线程间调用) : 关注的是消息通信机制
同步: synchronous, 调用者等待被调用者返回消息, 才能继续执行
异步: asynchronous, 被调用者通过状态、通知或回调机制主动通知调用者被调用者的运行状态
阻塞/非阻塞 (线程内调用) : 关注调用者在等待结果返回之前所处的状态
阻塞: blocking, 指 IO 操作需要彻底完成后才返回到用户空间, 调用结果返回之前, 调用者被挂起
非阻塞: nonblocking, 指 IO 操作被调用后立即返回给用户一个状态值, 无需等到 IO 操作彻底完成, 最终的调用结果返回之前, 调用者不会被挂起
同步阻塞: 你到饭馆点餐, 然后在那等着, 还要一边问: 好了没啊!
同步非阻塞: 在饭馆点完餐, 就去遛狗了, 不过溜一会儿, 就回饭馆问一下: 好了没啊!
异步阻塞: 你到饭馆点餐, 然后在那等着, 饭做好了, 服务员会叫号, 不需要你问.
异步非阻塞: 在饭馆点完餐, 就去遛狗了, 饭做好了, 服务员会打电话通知, 不需要你到饭店问.
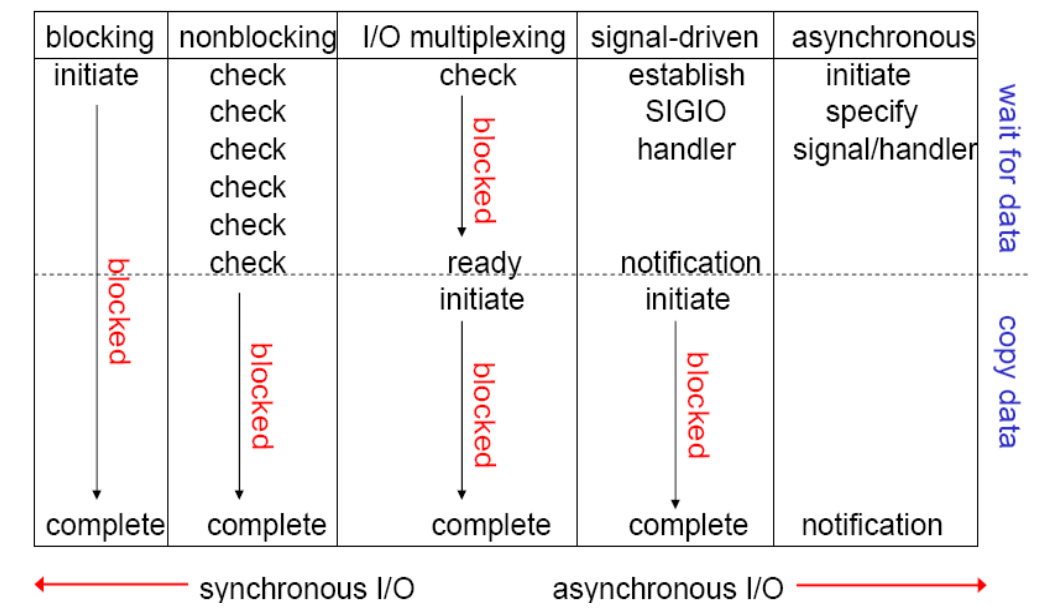
五种 I/O 模型 (操作系统) 阻塞 IO 模型、非阻塞 IO 模型、IO 复用模型、信号驱动 IO 模型、异步 IO 模型
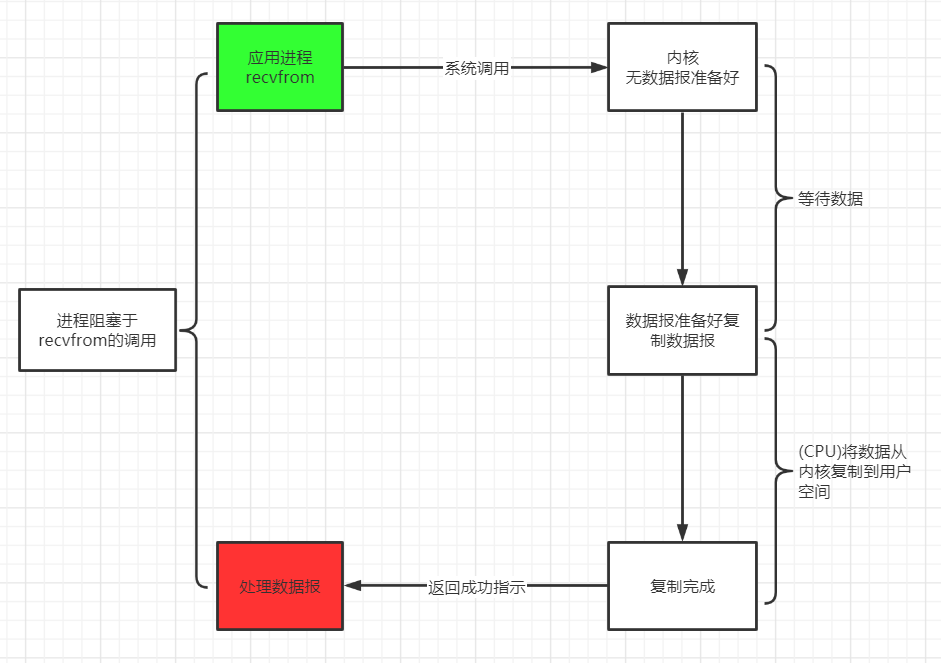
阻塞 IO 模型 阻塞 I/O 是最简单的 I/O 模型, 一般表现为进程或线程等待某个条件, 如果条件不满足, 则一直等下去. 条件满足, 则进行下一步操作.
应用进程通过系统调用 recvfrom 接收数据, 但由于内核还未准备好数据报, 应用进程就会阻塞住, 直到内核准备好数据报, recvfrom 完成数据报复制工作, 应用进程才能结束阻塞状态.
举例 我们钓鱼的时候, 有一种方式比较惬意, 比较轻松, 那就是我们坐在鱼竿面前, 这个过程中我们什么也不做, 双手一直把着鱼竿, 就静静的等着鱼儿咬钩. 一旦手上感受到鱼的力道, 就把鱼钓起来放入鱼篓中. 然后再钓下一条鱼.
这种钓鱼方式相对来说比较简单, 对于钓鱼的人来说, 不需要什么特制的鱼竿, 拿一根够长的木棍就可以悠闲的开始钓鱼了 (实现简单) . 缺点就是比较耗费时间, 比较适合那种对鱼的需求量小的情况 (并发低, 时效性要求低) .
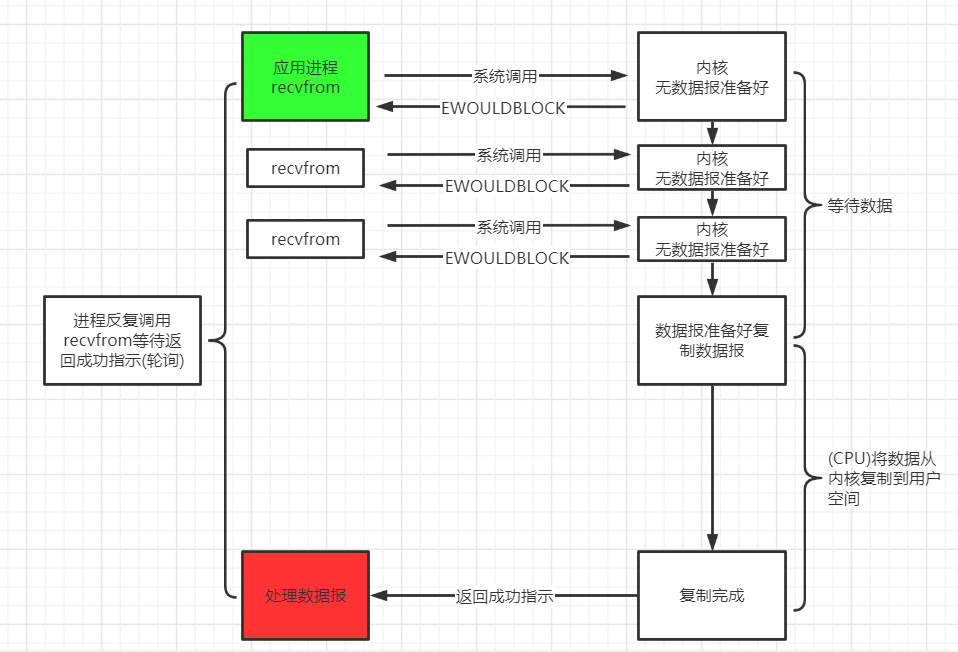
非阻塞 IO 模型 应用进程与内核交互, 目的未达到之前, 不再一味的等着, 而是直接返回. 然后通过轮询的方式, 不停的去问内核数据准备有没有准备好. 如果某一次轮询发现数据已经准备好了, 那就把数据拷贝到用户空间中.
应用进程通过 recvfrom 调用不停的去和内核交互, 直到内核准备好数据. 如果没有准备好, 内核会返回 error, 应用进程在得到 error 后, 过一段时间再发送 recvfrom 请求. 在两次发送请求的时间段, 进程可以先做别的事情.
举例 我们钓鱼的时候, 在等待鱼儿咬钩的过程中, 我们可以做点别的事情, 比如玩一把王者荣耀、看一集《延禧攻略》等等. 但是, 我们要时不时的去看一下鱼竿, 一旦发现有鱼儿上钩了, 就把鱼钓上来.
这种方式钓鱼, 和阻塞 IO 比, 所使用的工具没有什么变化, 但是钓鱼的时候可以做些其他事情, 增加时间的利用率.
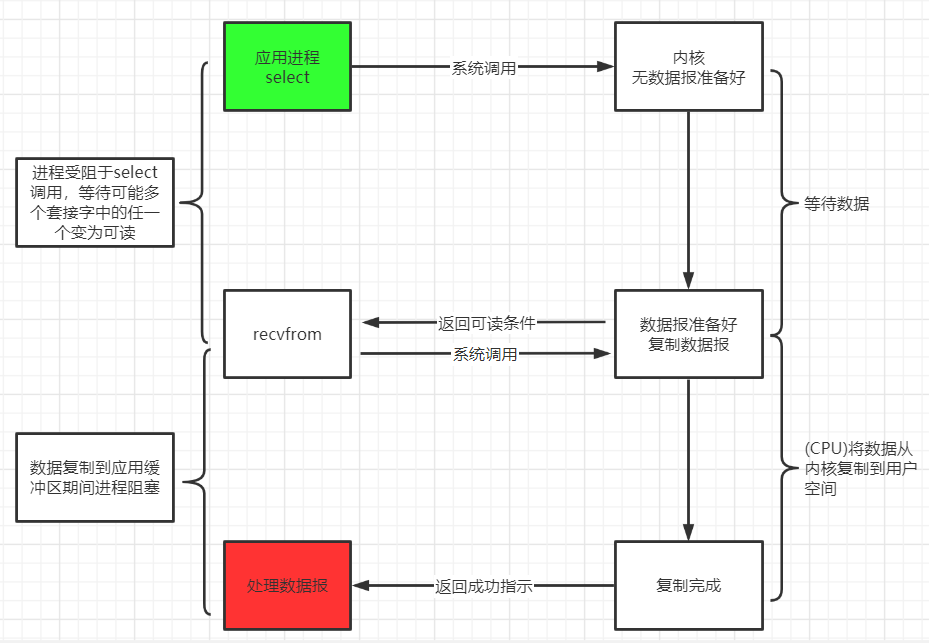
IO 复用模型 多个进程的 IO 可以注册到同一个管道上, 这个管道会统一和内核进行交互. 当管道中的某一个请求需要的数据准备好之后, 进程再把对应的数据拷贝到用户空间中.
IO 多路转接是多了一个 select 函数, 多个进程的 IO 可以注册到同一个 select 上, 当用户进程调用该 select, select 会监听所有注册好的 IO, 如果所有被监听的 IO 需要的数据都没有准备好时, select 调用进程会阻塞. 当任意一个 IO 所需的数据准备好之后, select 调用就会返回, 然后进程在通过 recvfrom 来进行数据拷贝.
**这里的 IO 复用模型, 并没有向内核注册信号处理函数, 所以, 它并不是非阻塞的. **进程在发出 select 后, 要等到 select 监听的所有 IO 操作中至少有一个需要的数据准备好, 才会有返回, 并且也需要再次发送请求去进行文件的拷贝.
举例 我们钓鱼的时候, 为了保证可以最短的时间钓到最多的鱼, 我们同一时间摆放多个鱼竿, 同时钓鱼. 然后哪个鱼竿有鱼儿咬钩了, 我们就把哪个鱼竿上面的鱼钓起来.
这种方式的钓鱼, 通过增加鱼竿的方式, 可以有效的提升效率.
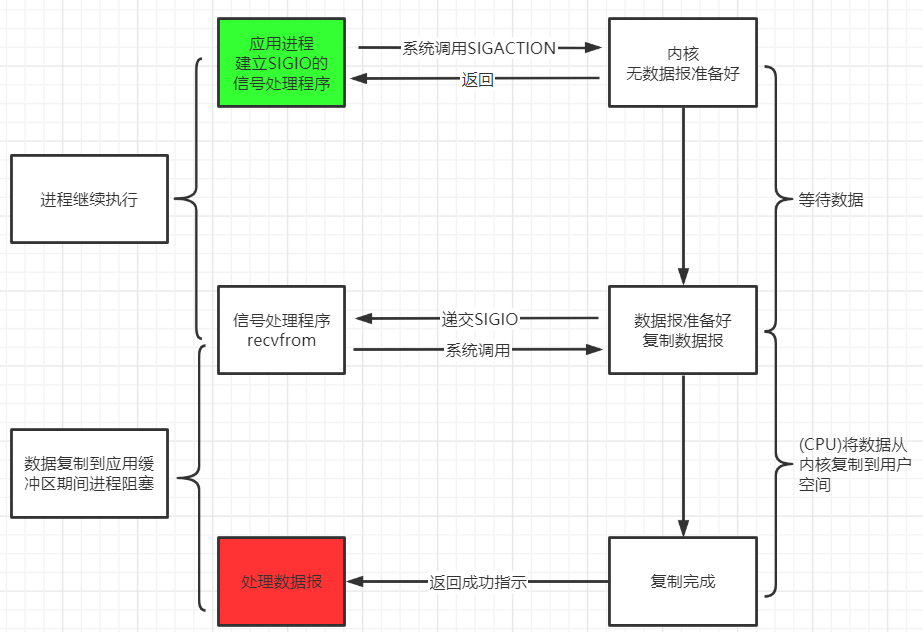
信号驱动 IO 模型 应用进程在读取文件时通知内核, 如果某个 socket 的某个事件发生时, 请向我发一个信号. 在收到信号后, 信号对应的处理函数会进行后续处理.
应用进程预先向内核注册一个信号处理函数, 然后用户进程返回, 并且不阻塞, 当内核数据准备就绪时会发送一个信号给进程, 用户进程便在信号处理函数中开始把数据拷贝的用户空间中.
举例 我们钓鱼的时候, 为了避免自己一遍一遍的去查看鱼竿, 我们可以给鱼竿安装一个报警器. 当有鱼儿咬钩的时候立刻报警. 然后我们再收到报警后, 去把鱼钓起来.
这种方式钓鱼, 和前几种相比, 所使用的工具有了一些变化, 需要有一些定制 (实现复杂) . 但是钓鱼的人就可以在鱼儿咬钩之前彻底做别的事儿去了. 等着报警器响就行了.
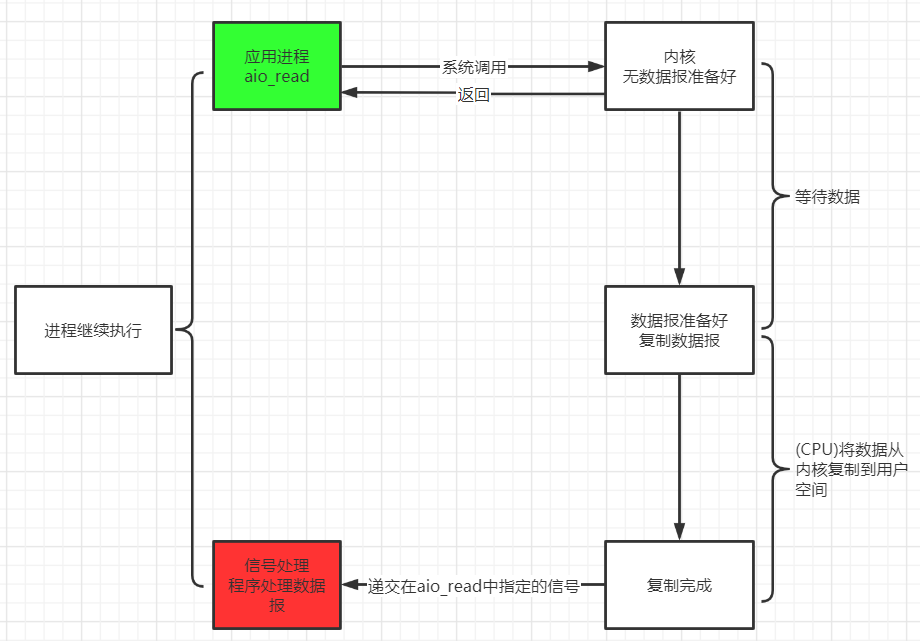
异步 IO 模型 应用进程把 IO 请求传给内核后, 完全由内核去操作文件拷贝. 内核完成相关操作后, 会发信号告诉应用进程本次 IO 已经完成.
用户进程发起 aio_read 操作之后, 给内核传递描述符、缓冲区指针、缓冲区大小等, 告诉内核当整个操作完成时, 如何通知进程, 然后就立刻去做其他事情了. 当内核收到 aio_read 后, 会立刻返回, 然后内核开始等待数据准备, 数据准备好以后, 直接把数据拷贝到用户控件, 然后再通知进程本次 IO 已经完成.
举例 我们钓鱼的时候, 采用一种高科技钓鱼竿, 即全自动钓鱼竿. 可以自动感应鱼上钩, 自动收竿, 更厉害的可以自动把鱼放进鱼篓里. 然后, 通知我们鱼已经钓到了, 他就继续去钓下一条鱼去了.
这种方式的钓鱼, 无疑是最省事儿的. 啥都不需要管, 只需要交给鱼竿就可以了.
5 种 IO 模型对比 阻塞 IO 模型、非阻塞 IO 模型、IO 复用模型和信号驱动 IO 模型都是同步的 IO 模型. 原因是无论以上哪种模型, 真正的数据拷贝过程, 都是同步进行的.
信号驱动难道不是异步的么?
信号驱动, 内核是在数据准备好之后通知进程, 然后进程再通过 recvfrom 操作进行数据拷贝. 我们可以认为数据准备阶段是异步的, 但是, 数据拷贝操作是同步的. 所以, 整个 IO 过程也不能认为是异步的.
举例 我们把钓鱼过程, 可以拆分为两个步骤: 1、鱼咬钩 (数据准备) . 2、把鱼钓起来放进鱼篓里 (数据拷贝) . 无论以上提到的哪种钓鱼方式, 在第二步, 都是需要人主动去做的, 并不是鱼竿自己完成的. 所以, 这个钓鱼过程其实还是同步进行的.
select、poll、epoll 对比 I/O多路复用底层主要用的Linux内核函数 (select,poll,epol) 来实现, windows 不支持 epoll 实现, windows 底层是基于 winsock2 的 select 函数实现的(不开源)
select
poll
epoll
性能
随着连接数的增加, 性能急剧下降, 处理成千上万的并发连接数时, 性能很差
随着连接数的增加, 性能急剧下降, 处理成千上万的并发连接数时, 性能很差
随着连接数的增加, 性能基本没有变化
连接数
默认1024
无限制, 但受到系统文件描述符个数限制
无限制
内存拷贝
每次调用select拷贝
每次调用poll拷贝
fd首次调用epoll_ctl拷贝, 每次调用epoll_wait不拷贝
数据结构
使用 BitsMap位图 的方式存储 fd_set, 支持的文件描述符个数受限 (由linux内核中的 FD_SETSIZE 限制)
动态数组, 以链表形式来组织
红黑树
内在处理机制
线性轮询
线性轮询
FD挂在红黑树, 通过事件回调callback
时间复杂度
O(n)
O(n)
O(1)
select, poll, epoll 都是 IO 多路复用的机制. I/O 多路复用就是通过一种机制, 一个进程可以监视多个描述符, 一旦某个描述符就绪 (一般是读就绪或者写就绪) , 能够通知程序进行相应的读写操作. 但 select, poll, epoll 本质上都是同步 I/O, 因为他们都需要在读写事件就绪后自己负责进行读写, 也就是说这个读写过程是阻塞的, 而异步 I/O 则无需自己负责进行读写, 异步 I/O 的实现会负责把数据从内核拷贝到用户空间.
select 1 int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout)
select 函数监视的文件描述符分 3 类, 分别是 writefds, readfds 和 exceptfds. 调用后 select 函数会阻塞, 直到有描述副就绪 (有数据 可读、可写、或者有 except) , 或者超时 (timeout 指定等待时间, 如果立即返回设为 null 即可) , 函数返回. 当 select 函数返回后, 可以通过遍历 fdset, 来找到就绪的描述符.
select 目前几乎在所有的平台上支持, 其良好跨平台支持也是它的一个优点. select 的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制, 在 Linux 上一般为 1024, 可以通过修改宏定义甚至重新编译内核的方式提升这一限制, 但是这样也会造成效率的降低.
poll 不同于 select 使用三个位图来表示三个 fdset 的方式, poll 使用一个 pollfd 的指针实现
1 2 3 4 5 6 7 int poll (struct pollfd *fds, unsigned int nfds, int timeout) struct pollfd { int fd; short events; short revents; };
pollfd 结构包含了要监视的 event 和发生的 event, 不再使用 select “参数-值” 传递的方式. 同时, pollfd 并没有最大数量限制 (但是数量过大后性能也是会下降) . 和 select 函数一样, poll 返回后, 需要轮询 pollfd 来获取就绪的描述符.
select/poll 总结 从上面看, select 和 poll 都需要在返回后, 通过遍历文件描述符来获取已经就绪的 socket. 事实上, 同时连接的大量客户端在一时刻可能只有很少的处于就绪状态, 因此随着监视的描述符数量的增长, 其效率也会线性下降.
使用方式:
在使用时, 首先要把关注的 Socket 集合通过 select/poll 系统调用从用户态拷贝到内核态
然后由内核检测事件, 当有网络事件产生时, 内核需要遍历进程关注的 Socket 集合, 找到有事件产生的 Socket, 并将其状态标记为 可读/可写
然后把整个 Socket 集合从内核态拷贝到用户态, 用户态还要再次遍历整个 Socket 集合找到被标记为 可读/可写 的 Socket, 然后对其处理
区别:
select 使用 BitsMap 位图的方式存储 fd_set, 支持的文件描述符个数受限 (由linux内核中的 FD_SETSIZE 限制), 默认为 1024, 只能监听 0~1023 的文件描述符
epoll epoll 是在 2.6 内核中提出的, 是之前的 select 和 poll 的增强版本. 相对于 select 和 poll 来说, epoll 更加灵活, 没有描述符限制. epoll 使用一个文件描述符管理多个描述符, 将用户关系的文件描述符的事件存放到内核的一个事件表中, 这样在用户空间和内核空间的 copy 只需一次.
epoll 操作过程 epoll 操作过程需要三个接口
1 2 3 int epoll_create (int size) int epoll_ctl (int epfd, int op, int fd, struct epoll_event *event) int epoll_wait (int epfd, struct epoll_event * events, int maxevents, int timeout)
int epoll_create(int size); 创建一个 epoll 的句柄, size 用来告诉内核这个监听的数目一共有多大, 这个参数不同于 select()中的第一个参数, 给出最大监听的 fd+1 的值, 参数 size 并不是限制了 epoll 所能监听的描述符最大个数, 只是对内核初始分配内部数据结构的一个建议.
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); 对指定描述符 fd 执行 op 操作
epfd: 是 epoll_create()的返回值
op: 表示 op 操作, 用三个宏来表示: 添加 EPOLL_CTL_ADD, 删除 EPOLL_CTL_DEL, 修改 EPOLL_CTL_MOD. 分别添加、删除和修改对 fd 的监听事件
fd: 是需要监听的 fd (文件描述符)
epoll_event: 是告诉内核需要监听什么事
struct epoll_event 结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 struct epoll_event { __uint32_t events; epoll_data_t data; }; EPOLLIN : 表示对应的文件描述符可以读 (包括对端SOCKET正常关闭); EPOLLOUT: 表示对应的文件描述符可以写; EPOLLPRI: 表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来); EPOLLERR: 表示对应的文件描述符发生错误; EPOLLHUP: 表示对应的文件描述符被挂断; EPOLLET: 将EPOLL设为边缘触发 (Edge Triggered) 模式, 这是相对于水平触发 (Level Triggered) 来说的. EPOLLONESHOT: 只监听一次事件, 当监听完这次事件之后, 如果还需要继续监听这个 socket 的话, 需要再次把这个socket加入到 EPOLL 队列里
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); 等待 epfd 上的 io 事件, 最多返回 maxevents 个事件.
参数 events 用来从内核得到事件的集合, maxevents 告之内核这个 events 有多大, 这个 maxevents 的值不能大于创建 epoll_create()时的 size, 参数 timeout 是超时时间 (毫秒, 0 会立即返回, -1 将不确定, 也有说法说是永久阻塞). 该函数返回需要处理的事件数目, 如返回 0 表示已超时.
epoll 工作模式 epoll 对文件描述符的操作有两种模式: LT (level trigger) 和 ET (edge trigger) . LT 模式是默认模式, LT 模式与 ET 模式的区别如下:
LT 模式 : 当 epoll_wait 检测到描述符事件发生并将此事件通知应用程序, 应用程序可以不立即处理该事件 . 下次调用 epoll_wait 时, 会再次响应应用程序并通知此事件.ET 模式 : 当 epoll_wait 检测到描述符事件发生并将此事件通知应用程序, 应用程序必须立即处理该事件 . 如果不处理, 下次调用 epoll_wait 时, 不会再次响应应用程序并通知此事件.
LT 模式 LT (level triggered) 是默认的工作方式, 并且同时支持 block 和 no-block socket. 在这种做法中, 内核告诉你一个文件描述符是否就绪了, 然后你可以对这个就绪的 fd 进行 IO 操作. 如果你不作任何操作, 内核还是会继续通知你的.
ET 模式 ET (edge-triggered) 是高速工作方式, 只支持 no-block socket. 在这种模式下, 当描述符从未就绪变为就绪时, 内核通过 epoll 告诉你. 然后它会假设你知道文件描述符已经就绪, 并且不会再为那个文件描述符发送更多的就绪通知, 直到你做了某些操作导致那个文件描述符不再为就绪状态了 (比如, 你在发送, 接收或者接收请求, 或者发送接收的数据少于一定量时导致了一个 EWOULDBLOCK 错误). 但是请注意, 如果一直不对这个 fd 作 IO 操作 (从而导致它再次变成未就绪) , 内核不会发送更多的通知 (only once)
ET 模式在很大程度上减少了 epoll 事件被重复触发的次数, 因此效率要比 LT 模式高. epoll 工作在 ET 模式的时候, 必须使用非阻塞套接口, 以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死
LT 和 ET 对比 假如有这样一个例子:
我们已经把一个用来从管道中读取数据的文件句柄(RFD)添加到 epoll 描述符
这个时候从管道的另一端被写入了 2KB 的数据
调用 epoll_wait(2), 并且它会返回 RFD, 说明它已经准备好读取操作
然后我们读取了 1KB 的数据
调用 epoll_wait(2)……
LT 模式
ET 模式 :
当使用 epoll 的 ET 模型来工作时, 当产生了一个 EPOLLIN 事件后,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 while (rs) { buflen = recv (activeevents[i].data.fd, buf, sizeof (buf), 0 ); if (buflen < 0 ) { if (errno == EAGAIN) { break ; } else { return ; } } else if (buflen == 0 ) { } if (buflen == sizeof (buf)) { rs = 1 ; } else { rs = 0 ; } }
Linux 中的 EAGAIN 含义 Linux 环境下开发经常会碰到很多错误(设置 errno), 其中 EAGAIN 是其中比较常见的一个错误(比如用在非阻塞操作中).
例如, 以 O_NONBLOCK 的标志打开文件/socket/FIFO, 如果你连续做 read 操作而没有数据可读. 此时程序不会阻塞起来等待数据准备就绪返回, read 函数会返回一个错误 EAGAIN, 提示你的应用程序现在没有数据可读请稍后再试.
epoll 总结 在 select/poll 中, 进程只有在调用一定的方法后, 内核才对所有监视的文件描述符进行扫描, 而epoll 事先通过 epoll_ctl()来注册一个文件描述符, 一旦基于某个文件描述符就绪时, 内核会采用类似 callback 的回调机制, 迅速激活这个文件描述符, 当进程调用 epoll_wait() 时便得到通知 . (此处去掉了遍历文件描述符, 而是通过监听回调的的机制. 这正是 epoll 的魅力所在. )
epoll 的优点主要是一下几个方面:
监视的描述符数量不受限制, 它所支持的 FD 上限是最大可以打开文件的数目, 这个数字一般远大于 2048,举个例子,在 1GB 内存的机器上大约是 10 万左右, 具体数目可以 cat /proc/sys/fs/file-max 查看,一般来说这个数目和系统内存关系很大. select 的最大缺点就是进程打开的 fd 是有数量限制的. 这对于连接数量比较大的服务器来说根本不能满足. 虽然也可以选择多进程的解决方案( Apache 就是这样实现的), 不过虽然 linux 上面创建进程的代价比较小, 但仍旧是不可忽视的, 加上进程间数据同步远比不上线程间同步的高效, 所以也不是一种完美的方案.
IO 的效率不会随着监视 fd 的数量的增长而下降. epoll 不同于 select 和 poll 轮询的方式, 而是通过每个 fd 定义的回调函数来实现的. 只有就绪的 fd 才会执行回调函数.
java 网络编程模型 java 支持 3 种网络编程模型: BIO、NIO、AIO.
BIO 同步并阻塞 (传统阻塞型), 服务器实现模式为一个连接一个线程, 即客户端有连接请求时服务器端就需要启动一个线程进行处理, 如果这个连接不作任何事情会造成不必要的线程开销, 可以通过线程池机制改善.
NIO 同步非阻塞 , 服务器实现模式为一个线程处理多个请求(连接), 即客户端发送的连接请求会被注册到多路复用器上, 多路复用器轮询到有 I/O 请求就会进行处理.
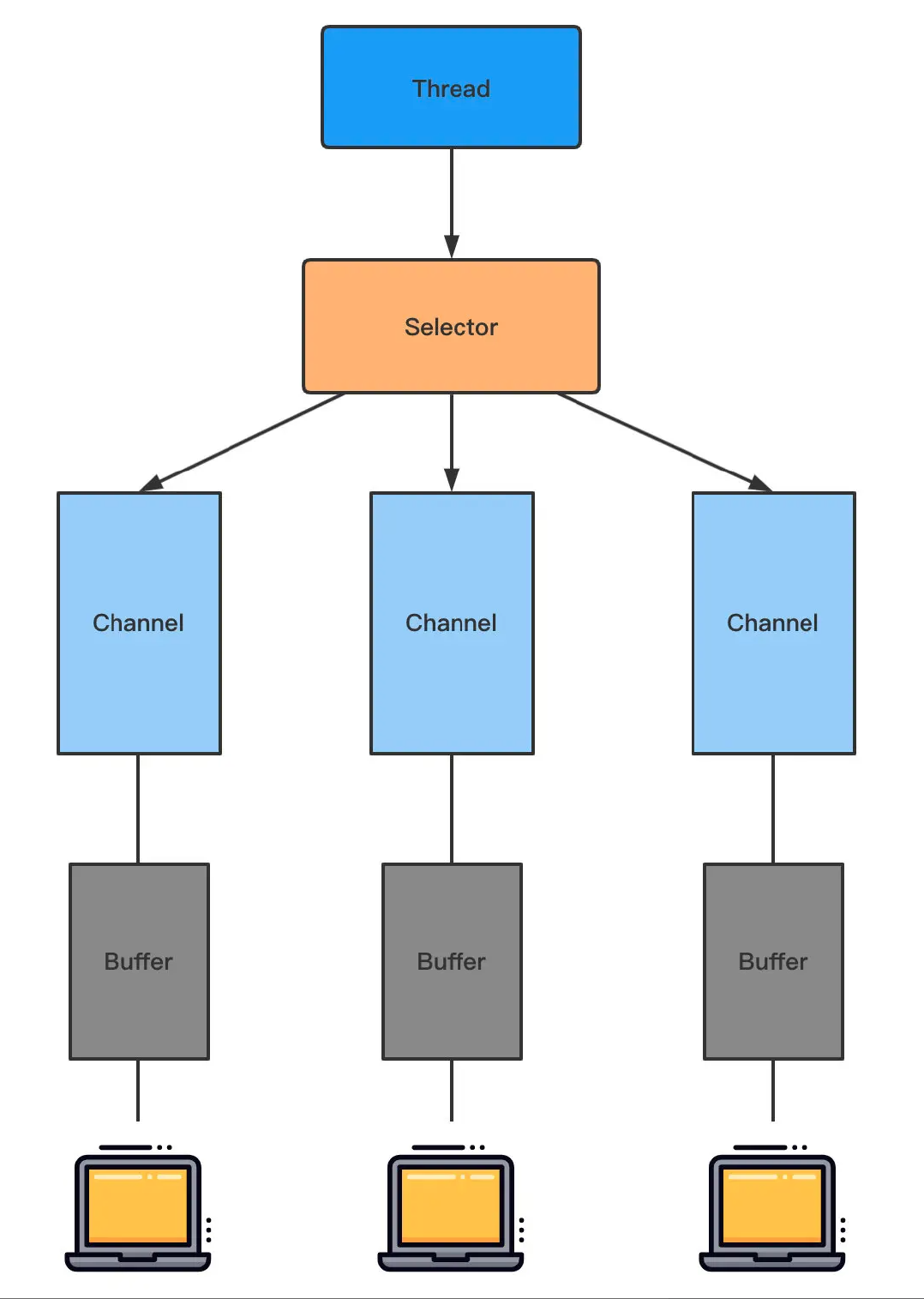
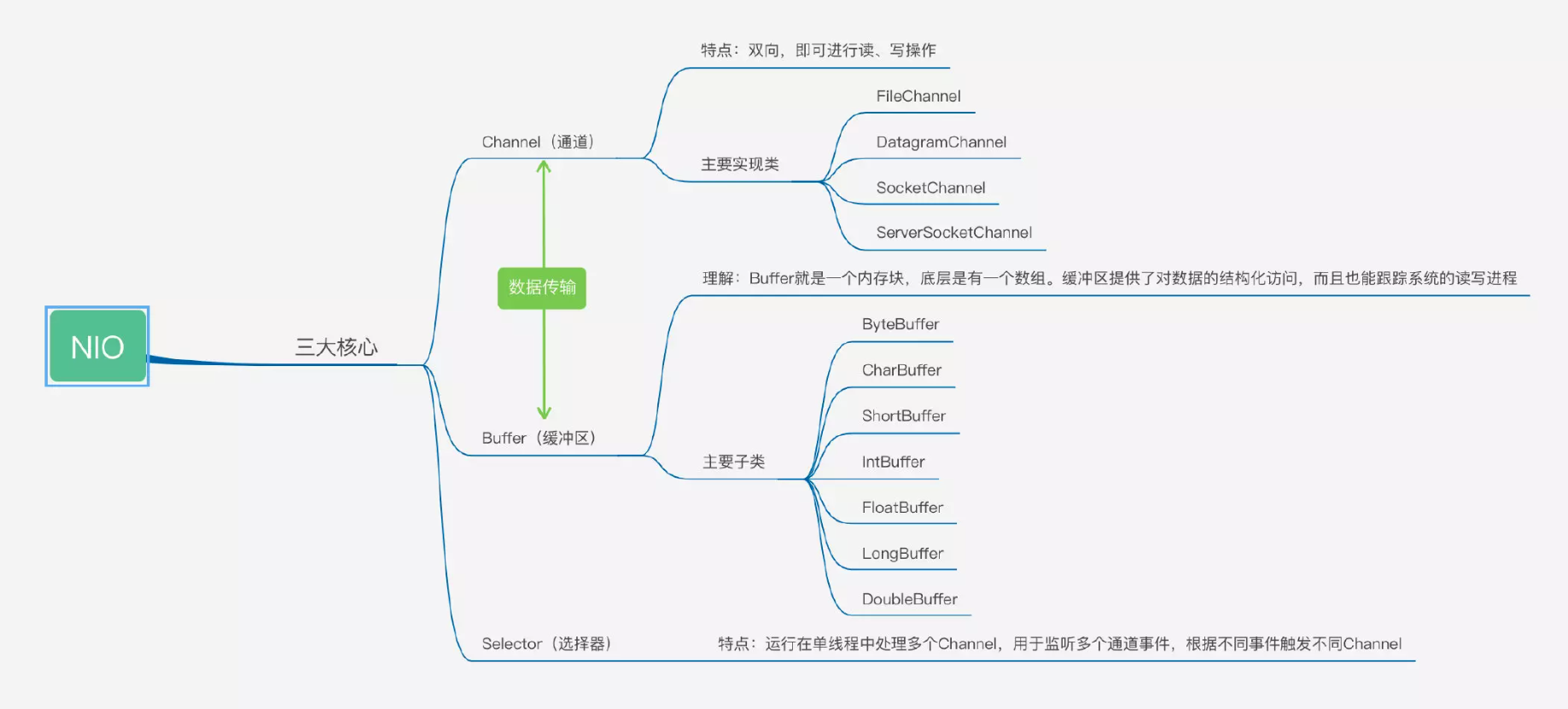
NIO 特性 NIO 主要有三大核心部分: Channel(通道), Buffer(缓冲区), Selector.
传统 IO 基于字节流和字符流进行操作, 而 NIO 基于 Channel 和 Buffer(缓冲区)进行操作, 数据总是从通道读取到缓冲区中, 或者从缓冲区写入到通道中.
Selector(选择区)用于监听多个通道的事件 (比如: 连接打开, 数据到达) . 因此, 单个线程可以监听多个数据通道
NIO 与 BIO 的区别
BIO 是面向流的, NIO 是面向缓冲区的.
BIO 流是阻塞的, NIO 流是非阻塞的.
BIO 基于字节流和字符流进行操作, 而 NIO 基于 Channel (通道) 和 Buffer (缓冲区) 进行操作, 数据总是从通道读取到缓冲区中, 或者从缓冲区写入到通道中.
NIO 有 Selector (选择器) , 而 BIO 没有. 选择器用于监听多个通道事件 (比如连接请求, 数据到达等) , 因此使用单个线程就可以监听多个客户端通道.
文件读取示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 public class IoTest { private static final Logger logger = LoggerFactory.getLogger(IoTest.class); public static void main (String[] args) { String filePath = ApplicationConfig.getInstance().getFilePath(); StringBuilder stringBuilder1 = readIo(filePath); writeIo(filePath, stringBuilder1); StringBuilder stringBuilder2 = readNio(filePath); writeNio(filePath, stringBuilder2); } private static StringBuilder readIo (String prePath) { InputStream is = null ; StringBuilder stringBuilder = new StringBuilder (); int mark = -1 ; String fileName = "io.txt" ; String filePath = prePath + fileName; try { is = new BufferedInputStream (new FileInputStream (filePath)); byte [] buffer = new byte [1024 ]; int readLength; ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); while ((readLength = is.read(buffer)) != mark) { byteArrayOutputStream.write(buffer, 0 , readLength); } stringBuilder.append(byteArrayOutputStream.toString("UTF-8" )); logger.info("文件 {} 的内容是: {}" , fileName, stringBuilder); } catch (IOException e) { logger.info("exception=" , e); } finally { if (is != null ) { try { is.close(); } catch (IOException e) { logger.info("exception=" , e); } } } return stringBuilder; } private static void writeIo (String prePath, StringBuilder stringBuilder) { String fileName = "io-io-out.txt" ; String filePath = prePath + fileName; OutputStream os = null ; try { byte [] bytes = stringBuilder.toString().getBytes(StandardCharsets.UTF_8); logger.info("bytes长度: {}" , bytes.length); os = new BufferedOutputStream (new FileOutputStream (filePath)); os.write(bytes); logger.info("写入文件: {}" , bytes.length); } catch (IOException e) { logger.info("exception=" , e); } finally { if (os != null ) { try { os.close(); } catch (IOException e) { logger.info("exception=" , e); } } } } private static StringBuilder readNio (String prePath) { FileInputStream fis = null ; StringBuilder stringBuilder = new StringBuilder (); int mark = -1 ; String fileName = "io.txt" ; String filePath = prePath + fileName; try { fis = new FileInputStream (filePath); FileChannel channel = fis.getChannel(); ByteBuffer byteBuffer = ByteBuffer.allocate(1024 ); int read; ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); while ((read = channel.read(byteBuffer)) != mark) { byteBuffer.flip(); byte [] temp = new byte [read]; byteBuffer.get(temp); byteArrayOutputStream.write(temp); byteBuffer.compact(); } stringBuilder.append(byteArrayOutputStream.toString("UTF-8" )); logger.info("文件 {} 的内容是: {}" , fileName, stringBuilder); } catch (IOException e) { logger.info("exception=" , e); } finally { if (fis != null ) { try { fis.close(); } catch (IOException e) { logger.info("exception=" , e); } } } return stringBuilder; } private static void writeNio (String prePath, StringBuilder stringBuilder) { String fileName = "io-nio-out.txt" ; String filePath = prePath + fileName; FileOutputStream fos = null ; try { ByteBuffer byteBuffer = ByteBuffer.wrap(stringBuilder.toString().getBytes(StandardCharsets.UTF_8)); logger.info("初始化容量: {}, limit: {}" , byteBuffer.capacity(), byteBuffer.limit()); fos = new FileOutputStream (filePath); FileChannel channel = fos.getChannel(); channel.write(byteBuffer); int length = 0 ; while ((length = channel.write(byteBuffer)) != 0 ) { logger.info("写入长度: {}" , length); } } catch (IOException e) { logger.info("exception=" , e); } finally { if (fos != null ) { try { fos.close(); } catch (IOException e) { logger.info("exception=" , e); } } } } }
NIO 三大核心关系
NIO 三大核心理解
Buffer 缓冲区 缓冲区本质上是一个可以读写数据的内存块, 可以理解为是一个容器对象 (含数组) , 该对象提供了一组方法, 可以更轻松地使用内存块, 缓冲区对象内置了一些机制, 能够跟踪和记录缓冲区的状态变化情况.
Channel 提供从文件、网络读取数据的渠道, 但是读取或者写入的数据都必须经过 Buffer.
Buffer 数据存储结构 在 Buffer 子类中维护着一个对应类型的数组, 用来存放数据
源码片段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package java.nio;public abstract class ByteBuffer extends Buffer implements Comparable <ByteBuffer> { final byte [] hb; final int offset; boolean isReadOnly; ByteBuffer(int mark, int pos, int lim, int cap, byte [] hb, int offset) { super (mark, pos, lim, cap); this .hb = hb; this .offset = offset; } ByteBuffer(int mark, int pos, int lim, int cap) { this (mark, pos, lim, cap, null , 0 ); } ...... }
Buffer 位置变量 Buffer 通过几个变量来保存这个数据的当前位置状态
capacity
容量, 即可以容纳的最大数据量; 在缓冲区被创建时候就被指定, 无法修改
limit
表示缓冲区的当前终点, 不能对缓冲区超过极限的位置进行读写操作, 但极限是可以修改的
position
当前位置, 下一个要被读或者写的索引, 每次读写缓冲区数据都会改变该值, 为下次读写做准备
mark
标记当前 position 位置, 当 reset 后回到标记位置.
源码片段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 package java.nio;import java.util.Spliterator;public abstract class Buffer { static final int SPLITERATOR_CHARACTERISTICS = Spliterator.SIZED | Spliterator.SUBSIZED | Spliterator.ORDERED; private int mark = -1 ; private int position = 0 ; private int limit; private int capacity; long address; Buffer(int mark, int pos, int lim, int cap) { if (cap < 0 ) throw new IllegalArgumentException ("Negative capacity: " + cap); this .capacity = cap; limit(lim); position(pos); if (mark >= 0 ) { if (mark > pos) throw new IllegalArgumentException ("mark > position: (" + mark + " > " + pos + ")" ); this .mark = mark; } } public final Buffer position (int newPosition) { if ((newPosition > limit) || (newPosition < 0 )) throw new IllegalArgumentException (); position = newPosition; if (mark > position) mark = -1 ; return this ; } public final Buffer limit (int newLimit) { if ((newLimit > capacity) || (newLimit < 0 )) throw new IllegalArgumentException (); limit = newLimit; if (position > limit) position = limit; if (mark > limit) mark = -1 ; return this ; } ...... }
Buffer 关键子类
Buffer
数据类型
ByteBuffer
byte
CharBuffer
char
DoubleBuffer
double
FloatBuffer
float
IntBuffer
int
LongBuffer
long
ShortBuffer
short
MappedByteBuffer
-
HeapByteBuffer
-
DirectByteBuffer
-
Buffer 方法
方法
描述
allocate(int capacity)
从堆空间中分配一个容量大小为 capacity 的 byte 数组作为缓冲区的 byte 数据存储器
allocateDirect(int capacity)
是不使用 JVM 堆栈而是通过操作系统来创建内存块用作缓冲区, 它与当前操作系统能够更好的耦合, 因此能进一步提高 I/O 操作速度. 但是分配直接缓冲区的系统开销很大, 因此只有在缓冲区较大并长期存在, 或者需要经常重用时, 才使用这种缓冲区
wrap(byte[] array)
这个缓冲区的数据会存放在 byte 数组中, bytes 数组或 buffer 缓冲区任何一方中数据的改动都会影响另一方. 其实 ByteBuffer 底层本来就有一个 bytes 数组负责来保存 buffer 缓冲区中的数据, 通过 allocate 方法系统会帮你构造一个 byte 数组
wrap(byte[] array, int offset, int length)
在上一个方法的基础上可以指定偏移量和长度, 这个 offset 也就是包装后 byteBuffer 的 position, 而 length 呢就是 limit-position 的大小, 从而我们可以得到 limit 的位置为 length+position(offset)
limit(), limit(10)等
其中读取和设置这 4 个属性的方法的命名和 jQuery 中的 val(),val(10)类似, 一个负责 get, 一个负责 set
reset()
把 position 设置成 mark 的值, 相当于之前做过一个标记, 现在要退回到之前标记的地方
clear()
position = 0;limit = capacity;mark = -1; 有点初始化的味道, 但是并不影响底层 byte 数组的内容
flip()
limit = position;position = 0;mark = -1; 翻转, 也就是让 flip 之后的 position 到 limit 这块区域变成之前的 0 到 position 这块, 翻转就是将一个处于存数据状态的缓冲区变为一个处于准备取数据的状态
rewind()
把 position 设为 0, mark 设为-1, 不改变 limit 的值
remaining()
return limit - position; 返回 limit 和 position 之间相对位置差
hasRemaining()
return position < limit 返回是否还有未读内容
compact()
把从 position 到 limit 中的内容移到 0 到 limit-position 的区域内, position 和 limit 的取值也分别变成 limit-position、capacity. 如果先将 positon 设置到 limit, 再 compact, 那么相当于 clear()
get()
相对读, 从 position 位置读取一个 byte, 并将 position+1, 为下次读写作准备
get(int index)
绝对读, 读取 byteBuffer 底层的 bytes 中下标为 index 的 byte, 不改变 position
get(byte[] dst, int offset, int length)
从 position 位置开始相对读, 读 length 个 byte, 并写入 dst 下标从 offset 到 offset+length 的区域
put(byte b)
相对写, 向 position 的位置写入一个 byte, 并将 postion+1, 为下次读写作准备
put(int index, byte b)
绝对写, 向 byteBuffer 底层的 bytes 中下标为 index 的位置插入 byte b, 不改变 position
put(ByteBuffer src)
用相对写, 把 src 中可读的部分 (也就是 position 到 limit) 写入此 byteBuffer
put(byte[] src, int offset, int length)
从 src 数组中的 offset 到 offset+length 区域读取数据并使用相对写写入此 byteBuffer
Channel 通道 Channel 和 IO 中的 Stream(流)类似, 但有如下区别:
通道是双向的可以进行读写, 而流是单向的只能读, 或者写.
通道可以实现异步读写数据.
通道可以从缓冲区读取数据, 也可以写入数据到缓冲区.
主要 Channel
Channel
用途
FileChannel
IO
DatagramChannel
UDP
SocketChannel
TCP(client)
ServerSocketChannel
TCP(server)
FileChannel 示例 FileChannel 主要用来对本地文件进行 IO 操作, 常见的方法有:
public int read(ByteBuffer dst) : 从通道中读取数据到缓冲区中.public int write(ByteBuffer src) : 把缓冲区中的数据写入到通道中.public long transferFrom(ReadableByteChannel src, long position, long count) : 从目标通道中复制数据到当前通道.public long transferTo(long position, long count, WriteableByteChannel target) : 把数据从当前通道复制给目标通道.
文件读写 stream 和 channel 示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 package test.java.io;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import test.ApplicationConfig;import java.io.*;import java.nio.ByteBuffer;import java.nio.channels.FileChannel;import java.nio.charset.StandardCharsets;public class IoTest { private static final Logger logger = LoggerFactory.getLogger(IoTest.class); public static void main (String[] args) { String filePath = ApplicationConfig.getInstance().getFilePath(); StringBuilder stringBuilder1 = readIo(filePath); writeIo(filePath, stringBuilder1); StringBuilder stringBuilder2 = readNio(filePath); writeNio(filePath, stringBuilder2); } private static StringBuilder readIo (String prePath) { InputStream is = null ; StringBuilder stringBuilder = new StringBuilder (); int mark = -1 ; String fileName = "io.txt" ; String filePath = prePath + fileName; try { is = new BufferedInputStream (new FileInputStream (filePath)); byte [] buffer = new byte [1024 ]; int readLength; ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); while ((readLength = is.read(buffer)) != mark) { byteArrayOutputStream.write(buffer, 0 , readLength); } stringBuilder.append(byteArrayOutputStream.toString("UTF-8" )); logger.info("文件 {} 的内容是: {}" , fileName, stringBuilder); } catch (IOException e) { logger.info("exception=" , e); } finally { if (is != null ) { try { is.close(); } catch (IOException e) { logger.info("exception=" , e); } } } return stringBuilder; } private static void writeIo (String prePath, StringBuilder stringBuilder) { String fileName = "io-io-out.txt" ; String filePath = prePath + fileName; OutputStream os = null ; try { byte [] bytes = stringBuilder.toString().getBytes(StandardCharsets.UTF_8); logger.info("bytes长度: {}" , bytes.length); os = new BufferedOutputStream (new FileOutputStream (filePath)); os.write(bytes); logger.info("写入文件: {}" , bytes.length); } catch (IOException e) { logger.info("exception=" , e); } finally { if (os != null ) { try { os.close(); } catch (IOException e) { logger.info("exception=" , e); } } } } private static StringBuilder readNio (String prePath) { FileInputStream fis = null ; StringBuilder stringBuilder = new StringBuilder (); int mark = -1 ; String fileName = "io.txt" ; String filePath = prePath + fileName; try { fis = new FileInputStream (filePath); FileChannel channel = fis.getChannel(); ByteBuffer byteBuffer = ByteBuffer.allocate(1024 ); int read; ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); while ((read = channel.read(byteBuffer)) != mark) { byteBuffer.flip(); byte [] temp = new byte [read]; byteBuffer.get(temp); byteArrayOutputStream.write(temp); byteBuffer.compact(); } stringBuilder.append(byteArrayOutputStream.toString("UTF-8" )); logger.info("文件 {} 的内容是: {}" , fileName, stringBuilder); } catch (IOException e) { logger.info("exception=" , e); } finally { if (fis != null ) { try { fis.close(); } catch (IOException e) { logger.info("exception=" , e); } } } return stringBuilder; } private static void writeNio (String prePath, StringBuilder stringBuilder) { String fileName = "io-nio-out.txt" ; String filePath = prePath + fileName; FileOutputStream fos = null ; try { ByteBuffer byteBuffer = ByteBuffer.wrap(stringBuilder.toString().getBytes(StandardCharsets.UTF_8)); logger.info("初始化容量: {}, limit: {}" , byteBuffer.capacity(), byteBuffer.limit()); fos = new FileOutputStream (filePath); FileChannel channel = fos.getChannel(); channel.write(byteBuffer); int length = 0 ; while ((length = channel.write(byteBuffer)) != 0 ) { logger.info("写入长度: {}" , length); } } catch (IOException e) { logger.info("exception=" , e); } finally { if (fos != null ) { try { fos.close(); } catch (IOException e) { logger.info("exception=" , e); } } } } }
通道间数据复制
直接复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 private static void channelCopy (String prePath) { String inFileName = "io.txt" ; String outFileName = "io-channel-copy.txt" ; String inFilePath = prePath + inFileName; String outFilePath = prePath + outFileName; FileInputStream fis = null ; FileOutputStream fos = null ; try { fis= new FileInputStream (inFilePath); fos = new FileOutputStream (outFilePath); FileChannel inChannel = fis.getChannel(); FileChannel outChannel = fos.getChannel(); ByteBuffer byteBuffer = ByteBuffer.allocate(1 ); while (inChannel.read(byteBuffer) != -1 ) { byteBuffer.flip(); outChannel.write(byteBuffer); byteBuffer.clear(); } } catch (IOException e) { logger.info("exception=" , e); } finally { if (fis != null ) { try { fis.close(); } catch (IOException e) { logger.info("exception=" , e); } } if (fos != null ) { try { fos.close(); } catch (IOException e) { logger.info("exception=" , e); } } } }
使用 transferFrom 或 transferTo 复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 private static void transferFromOrTo (String prePath) { String inFileName = "io.txt" ; String outFileName1 = "io-transfer-from.txt" ; String outFileName2 = "io-transfer-to.txt" ; String inFilePath = prePath + inFileName; String outFilePath1 = prePath + outFileName1; String outFilePath2 = prePath + outFileName2; FileInputStream fis = null ; FileOutputStream fos1 = null ; FileOutputStream fos2 = null ; try { fis= new FileInputStream (inFilePath); fos1 = new FileOutputStream (outFilePath1); fos2 = new FileOutputStream (outFilePath2); FileChannel inChannel = fis.getChannel(); FileChannel outChannel1 = fos1.getChannel(); FileChannel outChannel2 = fos2.getChannel(); outChannel1.transferFrom(inChannel, 0 , inChannel.size()); inChannel.transferTo(0 , inChannel.size(), outChannel2); } catch (IOException e) { logger.info("exception=" , e); } finally { if (fis != null ) { try { fis.close(); } catch (IOException e) { logger.info("exception=" , e); } } if (fos1 != null ) { try { fos1.close(); } catch (IOException e) { logger.info("exception=" , e); } } if (fos2 != null ) { try { fos2.close(); } catch (IOException e) { logger.info("exception=" , e); } } } }
Channel 和 Buffer 的注意事项
ByteBuffer 支持类型化的 put 和 get, put 放入什么数据类型, get 就应该使用相应的数据类型来取出, 否则可能会产生 ByteUnderflowException 异常.
可以将一个普通的 Buffer 转换为只读的 Buffer: asReadOnlyBuffer()方法.
NIO 提供了 MapperByteBuffer, 可以让文件直接在内存 (堆外内存) 中进行修改, 而如何同步到文件由 NIO 来完成.
NIO 还支持通过多个 Buffer(即 Buffer 数组)完成读写操作, 即 Scattering (分散) 和 Gathering (聚集) .
Scattering(分散): 在向缓冲区写入数据时, 可以使用 Buffer 数组依次写入, 一个 Buffer 数组写满后, 继续写入下一个 Buffer 数组.
Gathering(聚集): 从缓冲区读取数据时, 可以依次读取, 读完一个 Buffer 再按顺序读取下一个.
Selector 选择器 选择器是 NIO 的核心, 它是 channel 的管理者, 通过执行 select()阻塞方法, 监听是否有 channel 准备好, 一旦有数据可读, 此方法的返回值是 SelectionKey 的数量
所以服务端通常会死循环执行 select()方法, 直到有 channl 准备就绪, 然后开始工作, 每个 channel 都会和 Selector 绑定一个事件, 然后生成一个 SelectionKey 的对象
SelectionKey 一共有四种事件:
SelectionKey.OP_CONNECT: 连接事件
注意
channel 和 Selector 绑定时, channel 必须是非阻塞模式, 而 FileChannel 不能切换到非阻塞模式, 因为它不是套接字通道, 所以 FileChannel 不能和 Selector 绑定事件
Selector 常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public abstract class Selector implement Closeable{ public static Selector open () ; public abstract int select (long timeout) ; public abstract int select () ; public abstract int selectNow () ; public abstract Selector wakeup () ; public abstract Set<SelectionKey> selectionKeys () ; }
SelectionKey 当向 Selector 注册 Channel 时, register()方法会返回一个 SelectionKey 对象. 这个对象包含以下的属性:
interest 集合
ready 集合
Channel
Selector
附加的对象 (可选)
interest 集合: 是你所选择的感兴趣的事件集合. 可以通过 SelectionKey 读写 interest 集合.
1 int interestSet = selectionKey.interestOps();
ready 集合: 是通道已经准备就绪的操作的集合. 在一次选择(Selection)之后, 你会首先访问这个 ready set.
1 int readySet = selectionKey.readyOps();
检测 channel 中什么事件或操作已经就绪的方法:
selectionKey.isAcceptable();
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();
从 SelectionKey 访问 Channel 和 Selector:
1 2 Channel channel = selectionKey.channel();Selector selector = selectionKey.selector();
可以将一个对象或者更多信息附着到 SelectionKey 上, 这样就能方便的识别某个给定的通道. 例如, 可以附加与通道一起使用的 Buffer 或是包含聚集数据的某个对象. 使用方法如下:
1 2 selectionKey.attach(theObject); Object attachedObj = selectionKey.attachment();
还可以在用 register()方法向 Selector 注册 Channel 的时候附加对象. 如:
1 SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);
需要注意的是如果附加的对象不再使用, 一定要人为清除, 因为垃圾回收器不会回收该对象, 若不清除的话会成内存泄漏.
一个单独的通道可被注册到多个选择器中, 有些时候我们需要通过 isRegistered () 方法来检查一个通道是否已经被注册到任何一个选择器上. 通常来说, 我们并不会这么做.
NIO 事件
客户端的 SocketChannel 支持 OP_CONNECT, OP_READ, OP_WRITE 三个操作
服务端 ServerSocketChannel 只支持 OP_ACCEPT 操作
在服务端由 ServerSocketChannel 的 accept()方法产生的 SocketChannel 只支持 OP_READ, OP_WRITE 操作
client/Server
SocketChannel/ServerSocketChannel
OP_ACCEPT
OP_CONNECT
OP_WRITE
OP_READ
client
SocketChannel
Y
Y
Y
server
ServerSocketChannel
Y
server
SocketChannel
Y
Y
NIO 实现群聊 服务端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 package test.java.io;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.ByteArrayOutputStream;import java.io.IOException;import java.net.InetSocketAddress;import java.nio.ByteBuffer;import java.nio.channels.*;import java.nio.charset.StandardCharsets;import java.util.Iterator;public class NioServerTest { private static final Logger logger = LoggerFactory.getLogger(NioServerTest.class); public static void main (String[] args) { NioServerTest nioServerTest = new NioServerTest (); nioServerTest.init(); nioServerTest.listen(); } private Selector selector; private ServerSocketChannel listenChannel; private final int port = 8888 ; public void init () { try { selector = Selector.open(); listenChannel = ServerSocketChannel.open(); listenChannel.configureBlocking(false ); InetSocketAddress inetSocketAddress = new InetSocketAddress (this .port); listenChannel.socket().bind(inetSocketAddress); listenChannel.register(selector, SelectionKey.OP_ACCEPT); } catch (IOException e) { logger.warn("exception=" , e); } } public void listen () { while (true ) { try { selector.select(); } catch (IOException e) { logger.warn("exception=" , e); } Iterator<SelectionKey> iterator = selector.selectedKeys().iterator(); while (iterator.hasNext()) { SelectionKey key = iterator.next(); iterator.remove(); try { if (key.isAcceptable()) { this .accept(key); } else if (key.isReadable()) { this .read(key); } else if (key.isWritable() && key.isValid()) { this .write(key); } } catch (IOException e) { try { key.channel().close(); } catch (IOException ex) { logger.warn("exception=" , e); } logger.info("客户端断开了连接..." ); } } } } private void accept (SelectionKey key) throws IOException { logger.info("等待client连接..." ); ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel(); SocketChannel socketChannel = serverSocketChannel.accept(); socketChannel.configureBlocking(false ); SelectionKey rwKey = socketChannel.register(key.selector(), SelectionKey.OP_READ); ByteBuffer byteBuffer = ByteBuffer.allocate(1024 ); rwKey.attach(byteBuffer); } private void read (SelectionKey key) throws IOException { SocketChannel socketChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = (ByteBuffer) key.attachment(); ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); int read = socketChannel.read(byteBuffer); while (read > 0 ) { byteBuffer.flip(); byte [] data = new byte [read]; byteBuffer.get(data, 0 , read); byteArrayOutputStream.write(data); byteBuffer.compact(); read = socketChannel.read(byteBuffer); } if (read == -1 ) { socketChannel.close(); } String msg = new String (byteArrayOutputStream.toByteArray(), StandardCharsets.UTF_8); logger.info("client {} msg is: {}" , socketChannel.getRemoteAddress(), msg); transferInfo(msg, socketChannel); } private void transferInfo (String msg, SocketChannel selfChannel) { logger.info("服务器转发消息中..." ); for (SelectionKey key : selector.keys()) { Channel targetChannel = key.channel(); if (targetChannel instanceof SocketChannel && targetChannel != selfChannel) { ByteBuffer byteBuffer = (ByteBuffer) key.attachment(); byte [] data = msg.getBytes(StandardCharsets.UTF_8); if (byteBuffer.remaining() < data.length) { byteBuffer = reCapacity(byteBuffer, data.length); } byteBuffer.put(data); key.interestOps(key.interestOps() | SelectionKey.OP_WRITE); key.attach(byteBuffer); } } } private void write (SelectionKey key) throws IOException { SocketChannel socketChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = (ByteBuffer) key.attachment(); byteBuffer.flip(); while (byteBuffer.hasRemaining()) { socketChannel.write(byteBuffer); } byteBuffer.compact(); key.interestOps(key.interestOps() & ~SelectionKey.OP_WRITE); } private ByteBuffer reCapacity (ByteBuffer byteBuffer, int length) { int position = byteBuffer.position(); int destCapacity = byteBuffer.capacity(); while (destCapacity - position < length) { destCapacity <<= 1 ; } ByteBuffer destByteBuffer = ByteBuffer.allocate(destCapacity); byteBuffer.flip(); destByteBuffer.put(byteBuffer); byteBuffer.clear(); return destByteBuffer; } }
客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 package test.java.io;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.ByteArrayOutputStream;import java.io.IOException;import java.net.InetSocketAddress;import java.nio.ByteBuffer;import java.nio.channels.SelectionKey;import java.nio.channels.Selector;import java.nio.channels.SocketChannel;import java.nio.charset.StandardCharsets;import java.util.Iterator;import java.util.Scanner;import java.util.concurrent.Executors;public class NioClientTest { private static final Logger logger = LoggerFactory.getLogger(NioClientTest.class); public static void main (String[] args) { NioClientTest nioServerTest = new NioClientTest (); nioServerTest.init(); nioServerTest.listen(); } private Selector selector; private SelectionKey key; private final String host = "127.0.0.1" ; private final int port = 8888 ; public void init () { try { selector = Selector.open(); SocketChannel socketChannel = SocketChannel.open(); socketChannel.configureBlocking(false ); InetSocketAddress inetSocketAddress = new InetSocketAddress (host, port); socketChannel.connect(inetSocketAddress); key = socketChannel.register(selector, SelectionKey.OP_CONNECT); } catch (IOException e) { logger.warn("exception=" , e); } } public void listen () { Executors.newSingleThreadExecutor().execute(() -> { Scanner scanner = new Scanner (System.in); while (scanner.hasNextLine()) { ByteBuffer byteBuffer = (ByteBuffer) key.attachment(); byte [] data = scanner.nextLine().getBytes(StandardCharsets.UTF_8); if (byteBuffer.remaining() < data.length) { byteBuffer = reCapacity(byteBuffer, data.length); } byteBuffer.put(data); key.interestOps(key.interestOps() | SelectionKey.OP_WRITE); key.attach(byteBuffer); } }); while (true ) { try { selector.select(); } catch (IOException e) { logger.warn("exception=" , e); } Iterator<SelectionKey> iterator = selector.selectedKeys().iterator(); while (iterator.hasNext()) { SelectionKey key = iterator.next(); iterator.remove(); try { if (key.isConnectable()) { this .connect(key); } else if (key.isReadable()) { this .read(key); } else if (key.isWritable() && key.isValid()) { this .write(key); } } catch (IOException e) { try { key.channel().close(); } catch (IOException ex) { logger.warn("exception=" , e); } logger.info("服务器出现异常!!!" ); System.exit(-1 ); } } } } private void connect (SelectionKey key) throws IOException { SocketChannel socketChannel = (SocketChannel) key.channel(); if (socketChannel.isConnectionPending()) { socketChannel.finishConnect(); } socketChannel.configureBlocking(false ); String info = "this is connect message from client." ; ByteBuffer byteBuffer = ByteBuffer.allocate(1024 ); byteBuffer.clear(); byteBuffer.put(info.getBytes(StandardCharsets.UTF_8)); key.interestOps(key.interestOps() | SelectionKey.OP_READ | SelectionKey.OP_WRITE); key.attach(byteBuffer); } private void read (SelectionKey key) throws IOException { SocketChannel socketChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = (ByteBuffer) key.attachment(); ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); int read = socketChannel.read(byteBuffer); while (read > 0 ) { byteBuffer.flip(); byte [] data = new byte [read]; byteBuffer.get(data, 0 , read); byteArrayOutputStream.write(data); byteBuffer.compact(); read = socketChannel.read(byteBuffer); } if (read == -1 ) { socketChannel.close(); } String msg = new String (byteArrayOutputStream.toByteArray(), StandardCharsets.UTF_8); logger.info("server {} msg is: {}" , socketChannel.getRemoteAddress(), msg); } private void write (SelectionKey key) throws IOException { SocketChannel socketChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = (ByteBuffer) key.attachment(); byteBuffer.flip(); while (byteBuffer.hasRemaining()) { socketChannel.write(byteBuffer); } byteBuffer.compact(); key.interestOps(key.interestOps() & ~SelectionKey.OP_WRITE); } private ByteBuffer reCapacity (ByteBuffer byteBuffer, int length) { int position = byteBuffer.position(); int destCapacity = byteBuffer.capacity(); while (destCapacity - position < length) { destCapacity <<= 1 ; } ByteBuffer destByteBuffer = ByteBuffer.allocate(destCapacity); byteBuffer.flip(); destByteBuffer.put(byteBuffer); byteBuffer.clear(); return destByteBuffer; } }
AIO 异步非阻塞 , AIO 引入了异步通道的概念, 采用了 Proactor 模式, 简化了程序编写, 有效的请求才启动线程, 它的特点是先由操作系统完成后才通知服务端程序启动线程去处理, 一般适用于连接数较多且连接时间较长的应用.
BIO、NIO、AIO 使用场景分析
BIO 方式适用于连接数比较小且固定的架构, 这种方式对服务器资源要求比较高, 并发局限于应用中, JDK1.4 之前唯一的选择, 程序较为简单容易理解.
NIO 方式适用于连接数目多且连接比较短的架构, 比如聊天服务器, 弹幕系统, 服务器间通讯等, 编程比较复杂, JDK1.4 开始支持.
AIO 方式适用于连接数目多且连接比较长的架构, 比如相册服务器, 充分调用 OS 参与并发操作, 变成比较复杂, JDK7 开始支持.
参考资料:
漫话: 如何给女朋友解释什么是 Linux 的五种 IO 模型 理解什么是 BIO/NIO/AIO Netty 系列——NIO ByteBuffer 常用方法详解 Linux IO 模式及 select、poll、epoll 详解 Java NIO浅析