netty笔记
netty 简介
Netty 是一个高性能、异步事件驱动的 NIO 网络应用框架, 它提供了对 TCP、UDP 和文件传输的支持. 基于 Netty, 可以快速的开发和部署高性能、 高可用的网络服务端和客户端应用.
netty 优点
- 设计
- 针对多种传输类型的统一接口 - 阻塞和非阻塞
- 简单但更强大的线程模型
- 真正的无连接的数据报套接字支持
- 链接逻辑支持复用
- 易用性
- 大量的 Javadoc 和 代码实例
- API 使用简单, 开发门槛低 (对 IO 读写以及线程安全做了大量封装)
- 基于事件模式, 对网络事件进行串行化处理, 在保证高效的同时, 又降低了编程的复杂度
- 除了在 JDK 1.6 + 额外的限制. (一些特征是只支持在 Java 1.7 +. 可选的功能可能有额外的限制. )
- 功能
- 预置了多种编解码功能, 支持多种主流协议
- 定制能力强, 可以通过 ChannelHandler 对通信框架进行灵活地扩展
- 性能
- 比核心 Java API 更好的吞吐量, 较低的延时
- 资源消耗更少, 这个得益于共享池和重用
- 减少内存拷贝
- 健壮性
- 消除由于慢, 快, 或重载连接产生的 OutOfMemoryError
- 消除经常发现在 NIO 在高速网络中的应用中的不公平的读/写比
- 安全
- 完整的 SSL / TLS 和 StartTLS 的支持
- 运行在受限的环境例如 Applet 或 OSGI
- 社区
- 发布的更早和更频繁
- 社区驱动
与 mina 对比
- 都是 Trustin Lee 的作品, Netty 更晚, 也更成熟;
- Mina 将内核和一些特性的联系过于紧密, 使得用户在不需要这些特性的时候无法脱离, 相比下性能会有所下降, Netty 解决了这个设计问题;
- Netty 的文档更清晰, 很多 Mina 的特性在 Netty 里都有;
- Netty 更新周期更短, 新版本的发布比较快;
- 它们的架构差别不大, Mina 靠 apache 生存, 而 Netty 靠 jboss, 和 jboss 的结合度非常高, Netty 有对 google protocal buf 的支持, 有更完整的 ioc 容器支持(spring,guice,jbossmc 和 osgi);
- Netty 和 Mina 在处理 UDP 时有一些不同, Netty 将 UDP 无连接的特性暴露出来; 而 Mina 对 UDP 进行了高级层次的抽象, 可以把 UDP 当成”面向连接”的协议, 而要 Netty 做到这一点比较困难.
NIO 简介
NIO 主要有三大核心部分: Channel(通道), Buffer(缓冲区), Selector.
传统 IO 基于字节流和字符流进行操作, 而 NIO 基于 Channel 和 Buffer(缓冲区)进行操作, 数据总是从通道读取到缓冲区中, 或者从缓冲区写入到通道中.
Selector(选择区)用于监听多个通道的事件 (比如: 连接打开, 数据到达) . 因此, 单个线程可以监听多个数据通道
NIO 详细介绍参考: [io流]
NIO 与 IO 的区别
- IO 是面向流的, NIO 是面向缓冲区的
- IO 流是阻塞的, NIO 流是不阻塞的
- NIO 有选择器, 而 IO 没有
netty 组件
一个 netty 应用的常见组件:
- Bootstrap 和 ServerBootstrap
- NioEventLoop 和 NioEventLoopGroup
- Future 和 ChannelFuture
- ChannelPipeline
- Channel
- ChannelHandler
- ChannelHandlerContext
- ChannelInitializer
Bootstrap 和 ServerBootstrap
bootstrap 用于引导 Netty 的启动, Bootstrap 是客户端的引导类, ServerBootstrap 是服务端引导类.
NioEventLoop 和 NioEventLoopGroup
NioEventLoopGroup 可以理解为线程池, NioEventLoop 理解为一个线程, 每个 EventLoop 对应一个 Selector, 负责处理多个 Channel 上的事件.
Future 和 ChannelFuture
Netty 中的操作都是异步的, 等待完成或者注册监听.
ChannelPipeline
用于保存处理过程需要用到的 ChannelHandler 和 ChannelHandlerContext
ChannelPipeline 是一个 handler 的集合, 它负责处理和拦截出站和入站的事件和操作
ChannelPipeline 实现了拦截过滤器模式, 使用户能控制事件的处理方式
在 Netty 中, 每个 Channel 都有且只有一个 ChannelPipeline 与之对应
一个 Channel 包含了一个 ChannelPipeline, 而 ChannelPipeline 中又维护了一个由 ChannelHandlerContext 组成的双向链表, 并且每个 ChannelHandlerContext 中又关联着一个 ChannelHandler
read 事件(入站事件)和 write 事件(出站事件)在一个双向链表中, 入站事件会从链表 head 往后传递到最后一个入站的 handler, 出站事件会从链表 tail 往前传递到最前一个出站的 handler, 两种类型的 handler 互不干扰
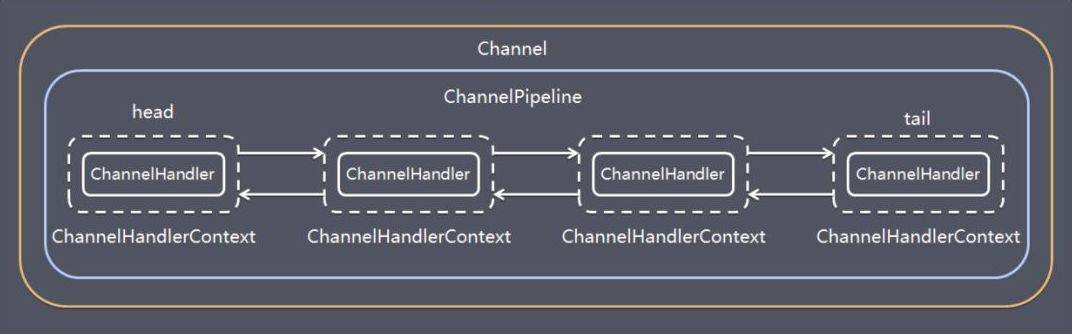
Channel
Netty 网络通信的组件, 用于网络 IO 操作, 表示一个连接, 可以理解为每一个连接, 就是一个 Channel
通过 Channel 可以获得当前网络连接的通道的状态与网络配置参数
Channel 提供异步的网络 IO 操作, 调用后立即返回 ChannelFuture, 通过注册监听, 或者同步等待, 最终获取结果
Channel 根据不同的协议、不同的阻塞类型, 分为不同的 Channel 类型
ChannelHandler
ChannelHandler 属于业务的核心接口, 用于处理 IO 事件或者拦截 IO 操作 (业务请求), 并将其转发到 ChannelPipeline (业务处理链) 中的下一个处理程序
ServerBootstrap 的 childHandler()与 handler()的区别
ServerBootstrap 的 childHandler() 与 handler() 添加的 handlers 是针对不同的 EventLoopGroup 起作用:
- 通过 handler 添加的 handlers 是对 bossGroup 线程组起作用
- 通过 childHandler 添加的 handlers 是对 workerGroup 线程组起作用
- handler 在初始化时就会执行, 而 childHandler 会在客户端成功 connect 后才执行, 这是两者的区别
**Bootstrap 的 handler()**:
- 客户端 Bootstrap 只有 handler()方法, 因为客户端只需要一个事件线程组
ChannelHandlerContext
用于传输业务数据, 保存 Channel 相关的所有上下文信息, 同时关联一个 ChannelHandler
ChannelInitializer
ChannelInitializer 是一个特殊的 ChannelInboundHandler, 当一个 Channel 被注册到它的 EventLoop 时, 提供一个简单的方式用于初始化.
它的实现类通常在 Bootstrap.handler(ChannelHandler)/ServerBootstrap.handler(ChannelHandler)和 ServerBootstrap.childHandler(ChannelHandler)的上下文中使用, 用于构建 channel 的 ChannelPipeline.
异常处理
类 ChannelInitializer 对异常处理的方式就是做两个事情:
- 打印日志
- 关闭 channel
1 |
|
当然子类可以继续覆盖这个实现. 不过一般都够用了.
netty 编解码
netty 涉及到编解码的组件有 Channel、ChannelHandler、ChannelPipe
编解码可以理解序列化和反序列化, 即: 序列化是把消息对象转换成字节码; 反序列化是把字节码再转换成消息对象
Netty 里面提供默认的编解码器, 也支持自定义编解码器
- Encoder: 编码器, 负责处理 “入站 InboundHandler” 数据
- Decoder: 解码器, 负责 “出站 OutboundHandler” 数据
编码器 Encoder
Encoder 对应的是 ChannelOutboundHandler, 消息对象转换为字节数组
Netty 本身未提供和解码一样的编码器, 是因为场景不同, 两者非对等的
Encoder 最重要的实现类是 MessageToByteEncoder<T>, 这个类的作用就是将消息实体 T 从对象转换成 byte, 写入到 ByteBuf, 然后再丢给剩下的 ChannelOutboundHandler 传给客户端
主要是一个方法:
encode: encode 方法是继承 MessageToByteEncoder 唯一需要重写的方法
抽象解码器
MessageToByteEncoder
消息转为字节数组,调用 write 方法, 会先判断当前编码器是否支持需要发送的消息类型, 如果不支持, 则透传
MessageToMessageEncoder
用于从一种消息编码为另外一种消息 (例如 POJO 到 POJO)
已实现解码器
StringEncoder
文本编码器, 将字符串编码为字节码
解码器 Decoder
Decoder 对应的是 ChannelInboundHandler, 主要是字节数组转换为消息对象
主要是两个方法:
- decode: ByteBuf 中有数据进来时调用
- decodeLast: 只有在 Channel 的生命周期结束之前会调用一次
抽象解码器
ByteToMessageDecoder
用于将字节转为消息, 需要检查缓冲区是否有足够的字节
ReplayingDecoder
ReplayingDecoder 是 byte-to-message 解码的一种特殊的抽象基类, 读取缓冲区的数据之前需要检查缓冲区是否有足够的字节, 使用 ReplayingDecoder 就无需自己检查; 若 ByteBuf 中有足够的字节, 则会正常读取; 若没有足够的字节则会停止解码.
RelayingDecoder 在使用的时候需要搞清楚的两个方法是 checkpoint(S s)和 state(), 其中 checkpoint 的参数 S, 代表的是 ReplayingDecoder 所处的状态, 一般是枚举类型. RelayingDecoder 是一个有状态的 Handler, 状态表示的是它目前读取到了哪一步, checkpoint(S s)是设置当前的状态, state()是获取当前的状态.
ReplayingDecoder 比 ByteToMessageDecoder 更加灵活, 能够通过巧妙的方式来处理复杂的业务逻辑, 但是也是因为这个原因, 使得 ReplayingDecoder 带有一定的局限性:
- 不是所有的标准 ByteBuf 操作都被支持, 如果调用一个不支持的操作会抛出 UnreplayableOperationException
- ReplayingDecoder 略慢于 ByteToMessageDecoder
示例
在这里我们模拟一个简单的 Decoder, 假设每个包包含 length:int 和 content:String 两个数据, 其中 length 可以为 0, 代表一个空包, 大于 0 的时候代表 content 的长度.
操作步骤:
- 继承 ReplayingDecoder, 泛型 LiveState, 用来表示当前读取的状态
- 描述 LiveState, 有读取长度和读取内容两个状态
- 初始化的时候设置为读取长度的状态
- 读取的时候通过 state()方法来确定当前处于什么状态
- 如果读取出来的长度大于 0, 则设置为读取内容状态, 下一次读取的时候则从这个位置开始
- 读取完成, 往结果里面放解析好的数据
1 | public class LiveDecoder extends ReplayingDecoder<LiveDecoder.LiveState> { //1 |
MessageToMessageDecoder
用于从一种消息解码为另外一种消息 (例如 POJO 到 POJO)
如何选择
如果不引入过多的复杂性则使用 ReplayingDecoder, 否则使用 ByteToMessageDecoder
已实现解码器
DelimiterBasedFrameDecoder
指定消息分隔符的解码器
LineBasedFrameDecoder
以换行符为结束标志的解码器
FixedLengthFrameDecoder
固定长度解码器
LengthFieldBasedFrameDecoder
message = header+body, 基于长度解码的通用解码器
StringDecoder
文本解码器, 将接收到的字节码转化为字符串, 一般会与上面的进行配合, 然后在后面添加业务 handle
TCP 粘包、拆包
TCP 是一个流协议, 就是没有界限的一长串二进制数据. TCP 作为传输层协议并不不了解上层业务数据的具体含义, 它会根据 TCP 缓冲区的实际情况进行数据包的划分, 所以在业务上认为是一个完整的包, 可能会被 TCP 拆分成多个包进行发送, 也有可能把多个小的包封装成一个大的数据包发送, 这就是所谓的 TCP 粘包和拆包问题. 面向流的通信是无消息保护边界的.
UDP: 是有边界协议, 没有粘包和拆包的问题
- TCP 拆包: 一个完整的包可能会被 TCP 拆分为多个包进行发送
- TCP 粘包: 把多个小的包封装成一个大的数据包发送, client 发送的若干数据包 Server 接收时粘成一包
发送方和接收方都可能出现这个原因:
- 发送方的原因: TCP 是流协议,TCP 默认会使用 Nagle 算法 (Nagle 算法就是为了尽可能发送大块数据, 避免网络中充斥着许多小数据块,当你连续发送小数据块的时候,他会收集到一定的大小才发出去)
- 接收方的原因: TCP 接收到数据放置缓存中, 应用程序从缓存中读取
如下图所示, client 发了两个数据包 D1 和 D2, 但是 server 端可能会收到如下几种情况的数据:
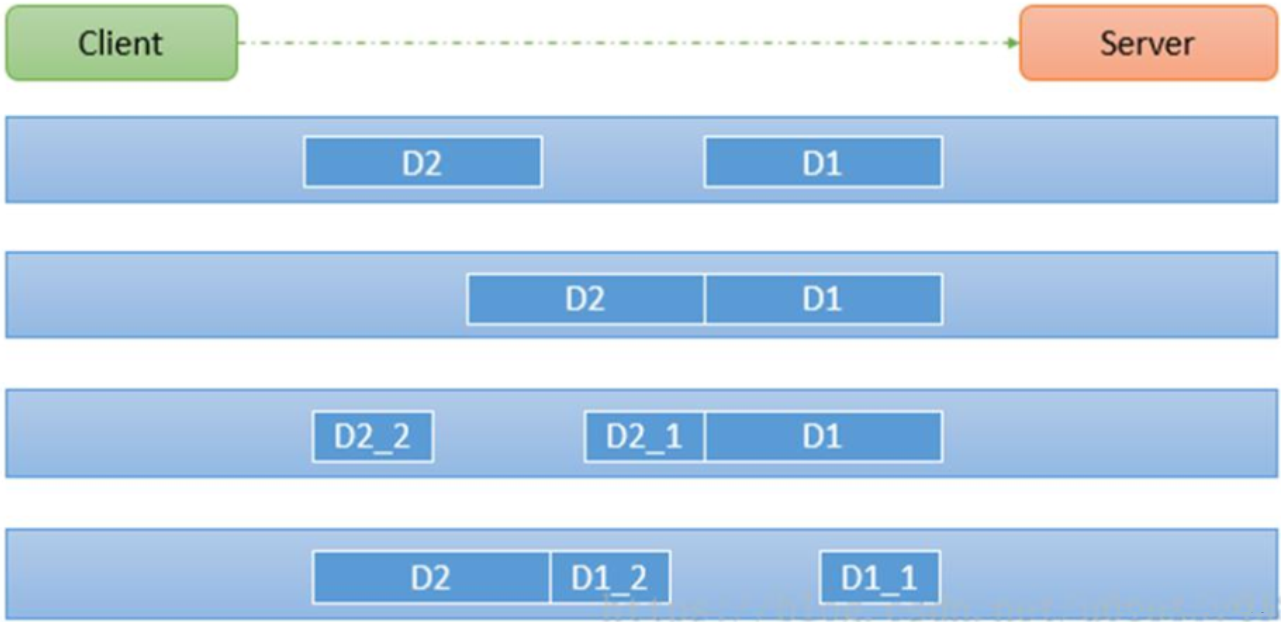
粘包、拆包解决方案
发送方
对于发送方造成的粘包问题, 可以通过关闭 Nagle 算法来解决, 使用 TCP_NODELAY 选项来关闭算法
接收方
接收方没有办法来处理粘包现象, 只能将问题交给应用层来处理
应用层
应用层的解决办法简单可行, 不仅能解决接收方的粘包问题, 还可以解决发送方的粘包问题
解决办法:
- 格式化数据: 每条数据有固定的格式 (开始符, 结束符) , 这种方法简单易行, 但是选择开始符和结束符时一定要确保每条数据的内部不包含开始符和结束符.
- 消息定长: 传输的数据大小固定长度, 例如每段的长度固定为 100 字节, 如果不够空位补空格.
- 发送长度: 发送每条数据时, 将数据的长度一并发送, 例如规定数据的前 4 位是数据的长度, 应用层在处理时可以根据长度来判断每个分组的开始和结束位置.
Netty 提供了多个解码器, 可以进行分包的操作, 如下:
- LineBasedFrameDecoder (回车换行分包)
- DelimiterBasedFrameDecoder (特殊分隔符分包)
- FixedLengthFrameDecoder (固定长度报文来分包)
这些分包解码器只需要放在我们的字符串解码器之前就好了,这些分包解码器也是入站 Handler,继承了我们的 InboundHandler:
粘包、拆包示例
1 | package test.io.netty.demo; |
部分输出:
1 | 20230411 160139.853 pid:test_project thread:nioEventLoopGroup-3-1 INFO [ChatServerHandler] 你好,我是Netty! |
由输出可以看到发生了粘包、拆包问题, 多个 “你好,我是 Netty!” 合并在了一起; 输出中的乱码是因为 “好” 字发生了拆包, UTF-8 的中文是 3 个字节, 3 个字节被拆分了两部分
UDP 丢包
主要丢包原因
- 接收端处理时间过长导致丢包: 调用 recv 方法接收端收到数据后, 处理数据花了一些时间, 处理完后再次调用 recv 方法, 在这二次调用间隔里,发过来的包可能丢失. 对于这种情况可以修改接收端, 将包接收后存入一个缓冲区, 然后迅速返回继续 recv.
- 发送的包巨大丢包: 虽然 send 方法会做大包切割成小包发送的事情, 但包太大也不行. 例如超过 50K 的一个 udp 包, 不切割直接通过 send 方法发送也会导致这个包丢失. 这种情况需要切割成小包再逐个 send.
- 发送的包较大: 超过接受者缓存导致丢包: 包超过 mtu size 数倍, 几个大的 udp 包可能会超过接收者的缓冲, 导致丢包. 这种情况可以设置 socket 接收缓冲. 遇到过这种问题, 可以把接收缓冲设置成 64K 解决.
int nRecvBuf=32*1024;//设置为 32Ksetsockopt(s,SOL_SOCKET,SO_RCVBUF,(const char*)&nRecvBuf,sizeof(int)); - 发送的包频率太快: 虽然每个包的大小都小于 mtu size 但是频率太快, 例如 40 多个 mut size 的包连续发送中间不 sleep, 也有可能导致丢包. 这种情况也有时可以通过设置 socket 接收缓冲解决, 但有时解决不了. 所以在发送频率过快的时候还是考虑 sleep 一下吧.
- 局域网内不丢包, 公网上丢包: 这个问题可以通过切割小包并 sleep 发送解决的. 如果流量太大, 这个办法也不灵了. 总之 udp 丢包总是会有的, 如果出现了切割小包的方法解决不了, 还有这个几个方法: 要么减小流量, 要么换 tcp 协议传输, 要么做丢包重传的工作.
netty 内存管理
为了减轻 GC 的压力、以及避免频繁向 OS 申请和释放内存, Netty 基于 JeMalloc 思想自己实现了一套内存管理方案. 不管是堆内存还是直接内存, 都可以交给 Netty 来统一管理, 这带来了两个好处, 一是可以减轻 GC 的压力, 二是可以避免向 OS 频繁申请和释放内存, Netty 一次性申请一大块内存, 然后按需分配.
**注意: ByteBuf 不等于内存, ByteBuf 是 Java 对象, 它工作需要内存做支撑. ByteBuf 本身通过 Recycler 来实现回收重用, 内存通过 JeMalloc 来进行管理复用. **
以 ByteBuf 为例, 网络 IO 的每次读写都需要 ByteBuf 支撑, 为了避免频繁的创建和销毁 ByteBuf, Netty 通过 Recycler 来回收对象进行重用. 同时为了避免频繁的申请和释放内存, Netty 通过 JeMalloc 技术来管理内存.
netty 零拷贝
零拷贝是一个耳熟能详的词语, 在 Linux、Kafka、RocketMQ 等知名的产品中都有使用, 通常用于提升 I/O 性能.
在介绍 netty 零拷贝之前简单熟悉一下 linux 零拷贝
Linux 零拷贝
所谓零拷贝, 就是在数据操作时, 不需要将数据从一个内存位置拷贝到另外一个内存位置, 这样可以减少一次内存拷贝的损耗, 从而节省了 CPU 时钟周期和内存带宽.
从文件中读取数据, 然后将数据传输到网络上, 传统的数据拷贝过程会分为以下几个阶段:
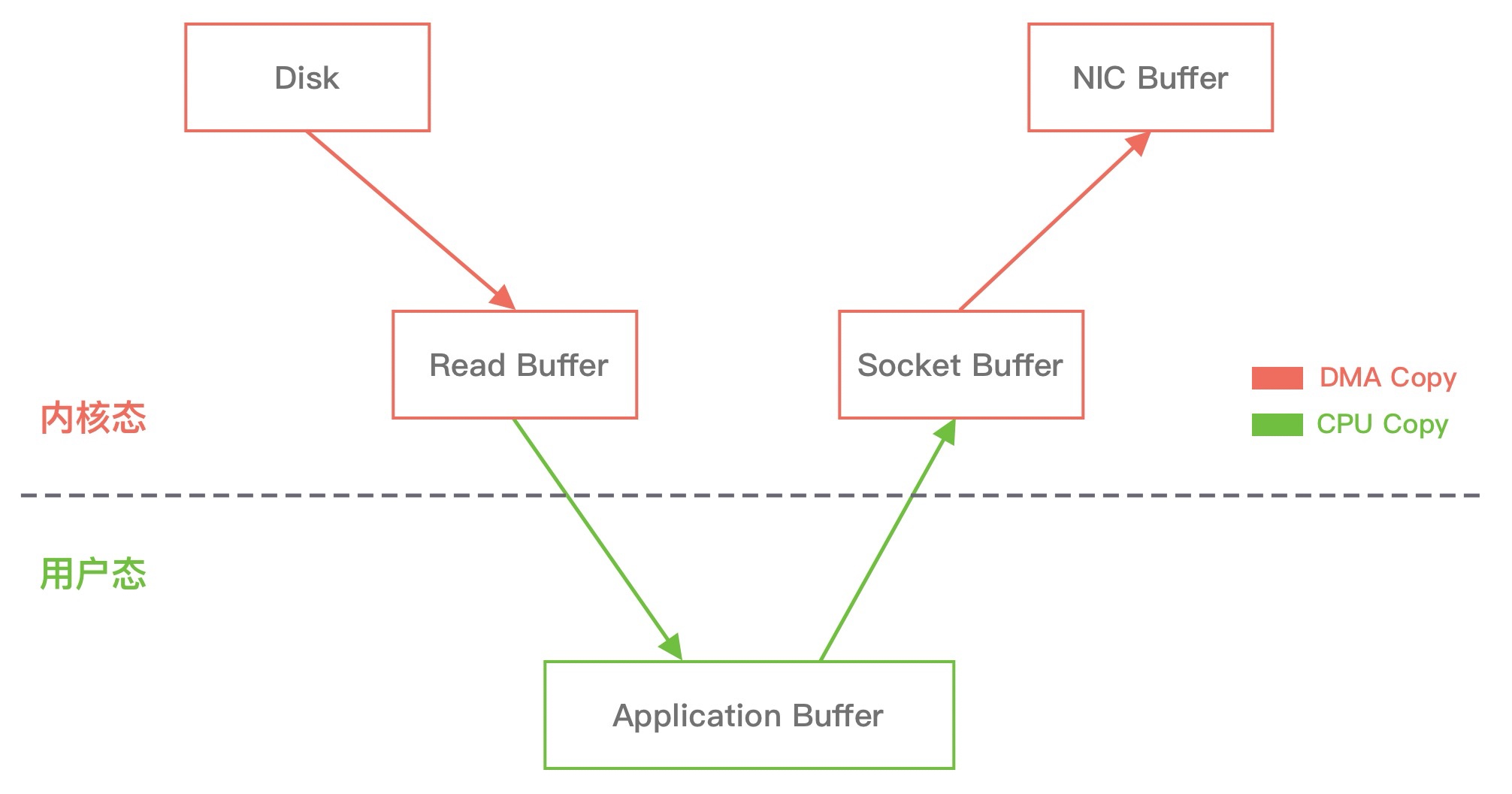
从上图中可以看出, 从数据读取到发送一共经历了四次数据拷贝, 具体流程如下:
- 当用户进程发起 read() 调用后, 上下文从用户态切换至内核态. DMA 引擎从文件中读取数据, 并存储到内核态缓冲区, 这里是第一次数据拷贝.
- 请求的数据从内核态缓冲区拷贝到用户态缓冲区, 然后返回给用户进程. 第二次数据拷贝的过程同时, 会导致上下文从内核态再次切换到用户态.
- 用户进程调用 send() 方法期望将数据发送到网络中, 此时会触发第三次线程切换, 用户态会再次切换到内核态, 请求的数据从用户态缓冲区被拷贝到 Socket 缓冲区.
- 最终 send() 系统调用结束返回给用户进程, 发生了第四次上下文切换. 第四次拷贝会异步执行, 从 Socket 缓冲区拷贝到协议引擎中.
说明: DMA (Direct Memory Access, 直接内存存取) 是现代大部分硬盘都支持的特性, DMA 接管了数据读写的工作, 不需要 CPU 再参与 I/O 中断的处理, 从而减轻了 CPU 的负担.
sendfile 模式
传统的数据拷贝过程为什么不是将数据直接传输到用户缓冲区呢? 其实引入内核缓冲区可以充当缓存的作用, 这样就可以实现文件数据的预读, 提升 I/O 的性能. 但是当请求数据量大于内核缓冲区大小时, 在完成一次数据的读取到发送可能要经历数倍次数的数据拷贝, 这就造成严重的性能损耗.
接下来我们介绍下使用零拷贝技术之后数据传输的流程: DMA 引擎从文件读取数据后放入到内核缓冲区, 然后可以直接从内核缓冲区传输到 Socket 缓冲区, 从而减少内存拷贝的次数.
在 Linux 中系统调用 sendfile() 可以实现将数据从一个文件描述符传输到另一个文件描述符, 从而实现了零拷贝技术. 在 Java 中也使用了零拷贝技术, 它就是 NIO FileChannel 类中的 transferTo() 方法, transferTo() 底层就依赖了操作系统零拷贝的机制, 它可以将数据从 FileChannel 直接传输到另外一个 Channel. transferTo() 方法的定义如下:
1 | // 把数据从当前通道复制给目标通道 |
transferTo() 详细用法可以参考: [io流] 中的 通道间数据复制 模块
在使用了 FileChannel#transferTo() 传输数据之后, 我们看下数据拷贝流程发生了哪些变化, 如下图所示:
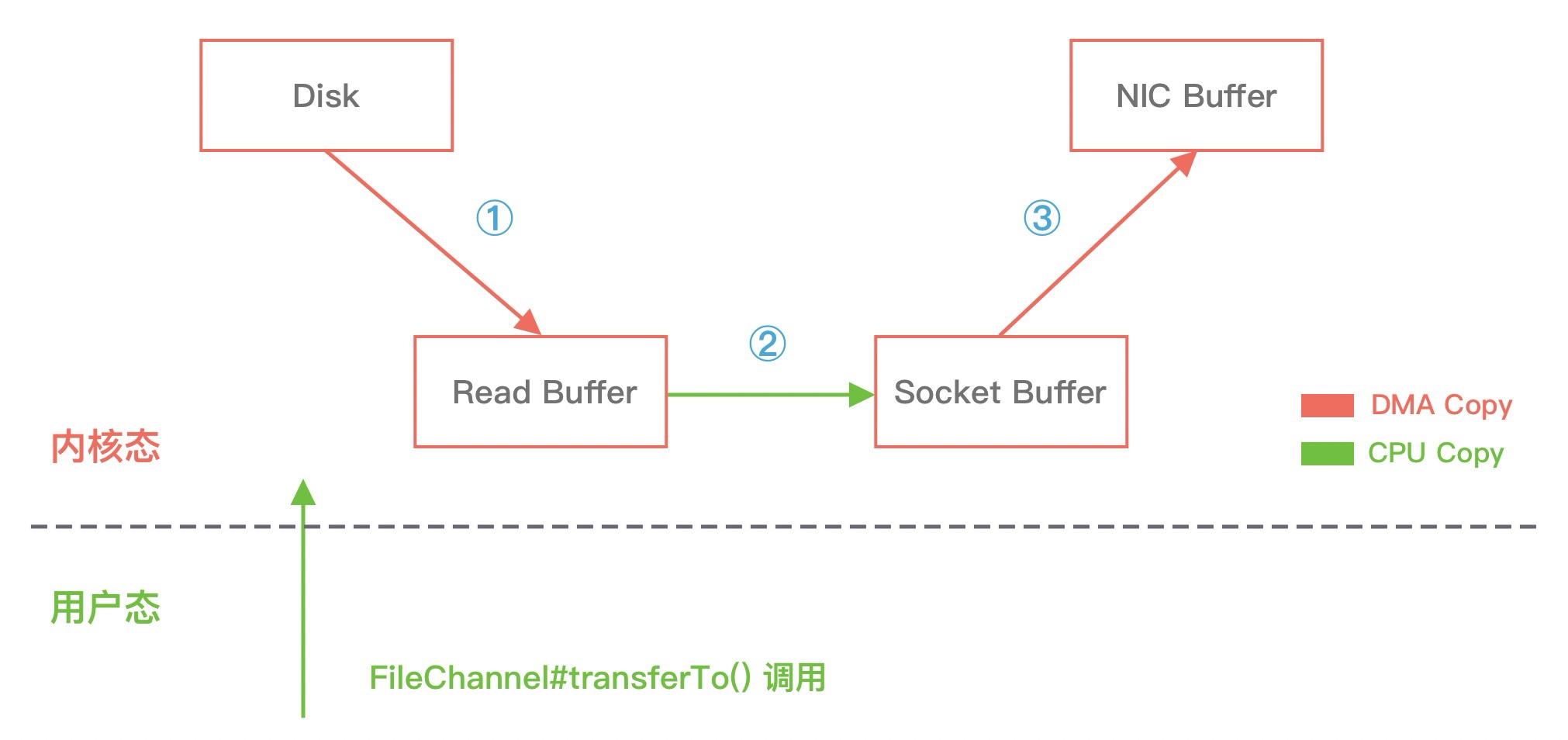
比较大的一个变化是, DMA 引擎从文件中读取数据拷贝到内核态缓冲区之后, 由操作系统直接拷贝到 Socket 缓冲区, 不再拷贝到用户态缓冲区, 所以数据拷贝的次数从之前的 4 次减少到 3 次.
**但是上述的优化离达到零拷贝的要求还是有差距的, 能否继续减少内核中的数据拷贝次数呢? **
sendfile + DMA gather copy 模式
Linux 2.4 版本对 sendfile 系统调用进行修改, 为 DMA 拷贝引入了 gather 操作. 它将内核空间 (kernel space) 的读缓冲区 (read buffer) 中对应的数据描述信息 (内存地址、地址偏移量) 记录到相应的网络缓冲区 ( socket buffer) 中, 由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区 (read buffer) 拷贝到网卡设备中. 这样就省去了内核空间中仅剩的 1 次 CPU 拷贝操作, sendfile 的伪代码如下:
1 | sendfile(socket_fd, file_fd, len); |
在硬件的支持下, sendfile 拷贝方式不再从内核缓冲区的数据拷贝到 socket 缓冲区, 取而代之的仅仅是缓冲区文件描述符和数据长度的拷贝, 这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可, 本质就是和虚拟内存映射的思路类似.
拷贝流程如下图所示:
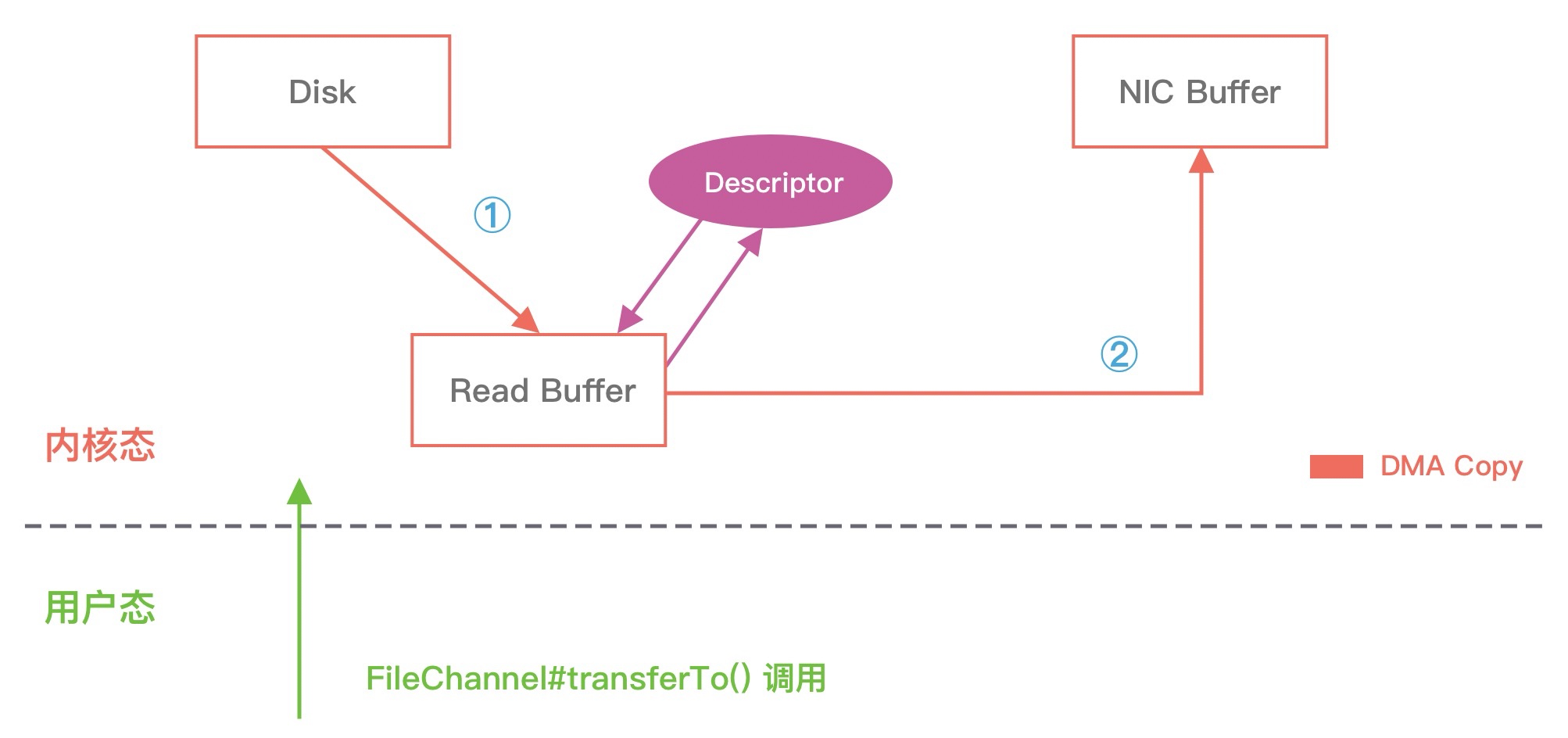
基于 sendfile + DMA gather copy 系统调用的零拷贝方式, 整个拷贝过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝, 用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核 (kernel) 发起系统调用, 上下文从用户态 (user space) 切换为内核态 (kernel space) .
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间 (kernel space) 的读缓冲区 (read buffer) .
- CPU 把读缓冲区 (read buffer) 的文件描述符 (file descriptor) 和数据长度拷贝到网络缓冲区 (socket buffer) .
- 基于已拷贝的文件描述符 (file descriptor) 和数据长度, CPU 利用 DMA 控制器的 gather/scatter 操作直接批量地将数据从内核的读缓冲区 (read buffer) 拷贝到网卡进行数据传输.
- 上下文从内核态 (kernel space) 切换回用户态 (user space) , sendfile 系统调用执行返回.
sendfile + DMA gather copy 拷贝方式同样存在用户程序不能对数据进行修改的问题, 而且本身需要硬件的支持, 它只适用于将数据从文件拷贝到 socket 套接字上的传输过程.
netty 零拷贝
介绍完传统 Linux 的零拷贝技术之后, 我们再来学习下 Netty 中的零拷贝如何实现. Netty 中的零拷贝和传统 Linux 的零拷贝不太一样. Netty 中的零拷贝技术除了操作系统级别的功能封装, 更多的是面向用户态的数据操作优化, 主要体现在以下 5 个方面:
- 堆外内存, 避免 JVM 堆内存到堆外内存的数据拷贝.
- CompositeByteBuf 类, 可以组合多个 Buffer 对象合并成一个逻辑上的对象, 避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer.
- 通过 Unpooled.wrappedBuffer 可以将 byte 数组包装成 ByteBuf 对象, 包装过程中不会产生内存拷贝.
- ByteBuf.slice 操作与 Unpooled.wrappedBuffer 相反, slice 操作可以将一个 ByteBuf 对象切分成多个 ByteBuf 对象, 切分过程中不会产生内存拷贝, 底层共享一个 byte 数组的存储空间.
- Netty 使用 FileRegion 实现文件传输, FileRegion 底层封装了 FileChannel#transferTo() 方法, 可以将文件缓冲区的数据直接传输到目标 Channel, 避免内核缓冲区和用户态缓冲区之间的数据拷贝, 这属于操作系统级别的零拷贝.
下面我们从以上 5 个方面逐一进行介绍.
堆外内存
如果在 JVM 内部执行 I/O 操作时, 必须将数据拷贝到堆外内存, 才能执行系统调用. 这是所有 VM 语言都会存在的问题. 那么为什么操作系统不能直接使用 JVM 堆内存进行 I/O 的读写呢? 主要有两点原因: 第一, 操作系统并不感知 JVM 的堆内存, 而且 JVM 的内存布局与操作系统所分配的是不一样的, 操作系统并不会按照 JVM 的行为来读写数据. 第二, 同一个对象的内存地址随着 JVM GC 的执行可能会随时发生变化, 例如 JVM GC 的过程中会通过压缩来减少内存碎片, 这就涉及对象移动的问题了.
Netty 在进行 I/O 操作时都是使用的堆外内存, 可以避免数据从 JVM 堆内存到堆外内存的拷贝.
Netty 也可以声明为堆内内存
CompositeByteBuf
CompositeByteBuf 是 Netty 中实现零拷贝机制非常重要的一个数据结构, CompositeByteBuf 可以理解为一个虚拟的 Buffer 对象, 它是由多个 ByteBuf 组合而成, 但是在 CompositeByteBuf 内部保存着每个 ByteBuf 的引用关系, 从逻辑上构成一个整体. 比较常见的像 HTTP 协议数据可以分为头部信息 header 和消息体数据 body, 分别存在两个不同的 ByteBuf 中, 通常我们需要将两个 ByteBuf 合并成一个完整的协议数据进行发送, 可以使用如下方式完成:
1 | // 初始化一个新的 ByteBuf |
可以看出合并过程中涉及两次 CPU 拷贝, 这非常浪费性能. 如果使用 CompositeByteBuf 如何实现类似的需求呢? 如下所示:
1 | // 初始化一个新的 CompositeByteBuf |
CompositeByteBuf 通过调用 addComponents() 方法来添加多个 ByteBuf, 但是底层的 byte 数组是复用的, 不会发生内存拷贝. 但对于用户来说, 它可以当作一个整体进行操作. 那么 CompositeByteBuf 内部是如何存放这些 ByteBuf, 并且如何进行合并的呢? 我们先通过一张图看下 CompositeByteBuf 的内部结构:
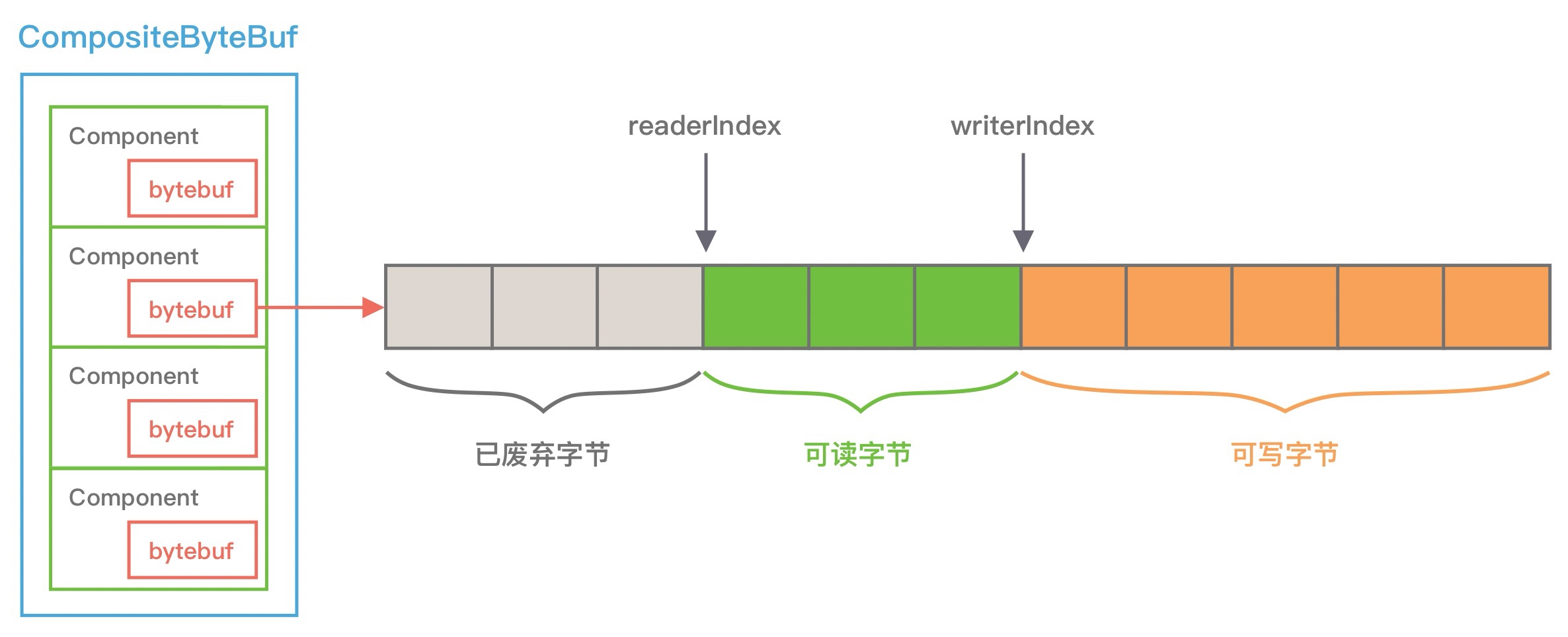
从图上可以看出, CompositeByteBuf 内部维护了一个 Components 数组. 在每个 Component 中存放着不同的 ByteBuf, 各个 ByteBuf 独立维护自己的读写索引, 而 CompositeByteBuf 自身也会单独维护一个读写索引. 由此可见, Component 是实现 CompositeByteBuf 的关键所在, 下面看下 Component 结构定义:
1 | private static final class Component { |
为了方便理解上述 Component 中的属性含义, 我同样以 HTTP 协议中 header 和 body 为示例, 通过一张图来描述 CompositeByteBuf 组合后其中 Component 的布局情况, 如下所示:
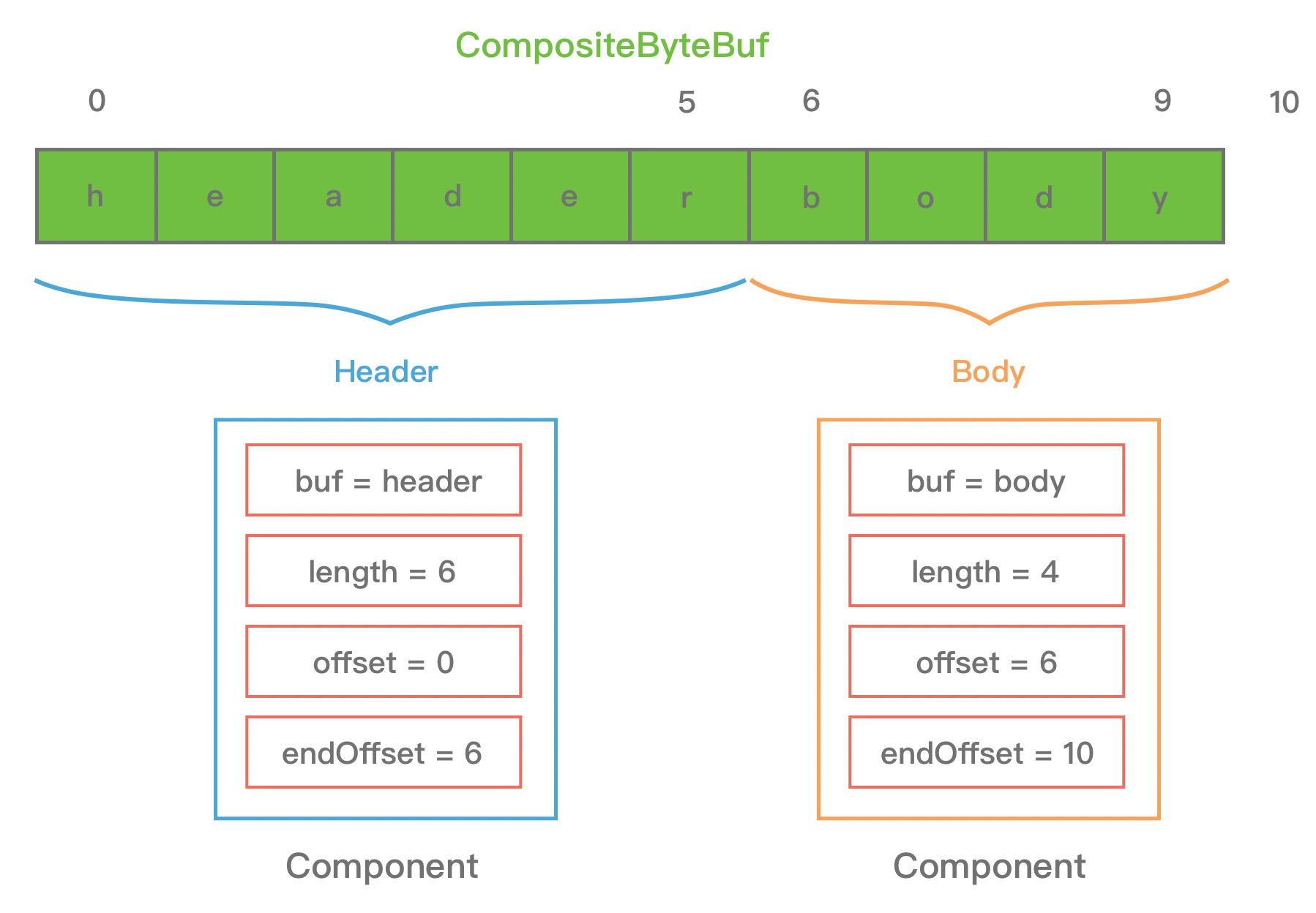
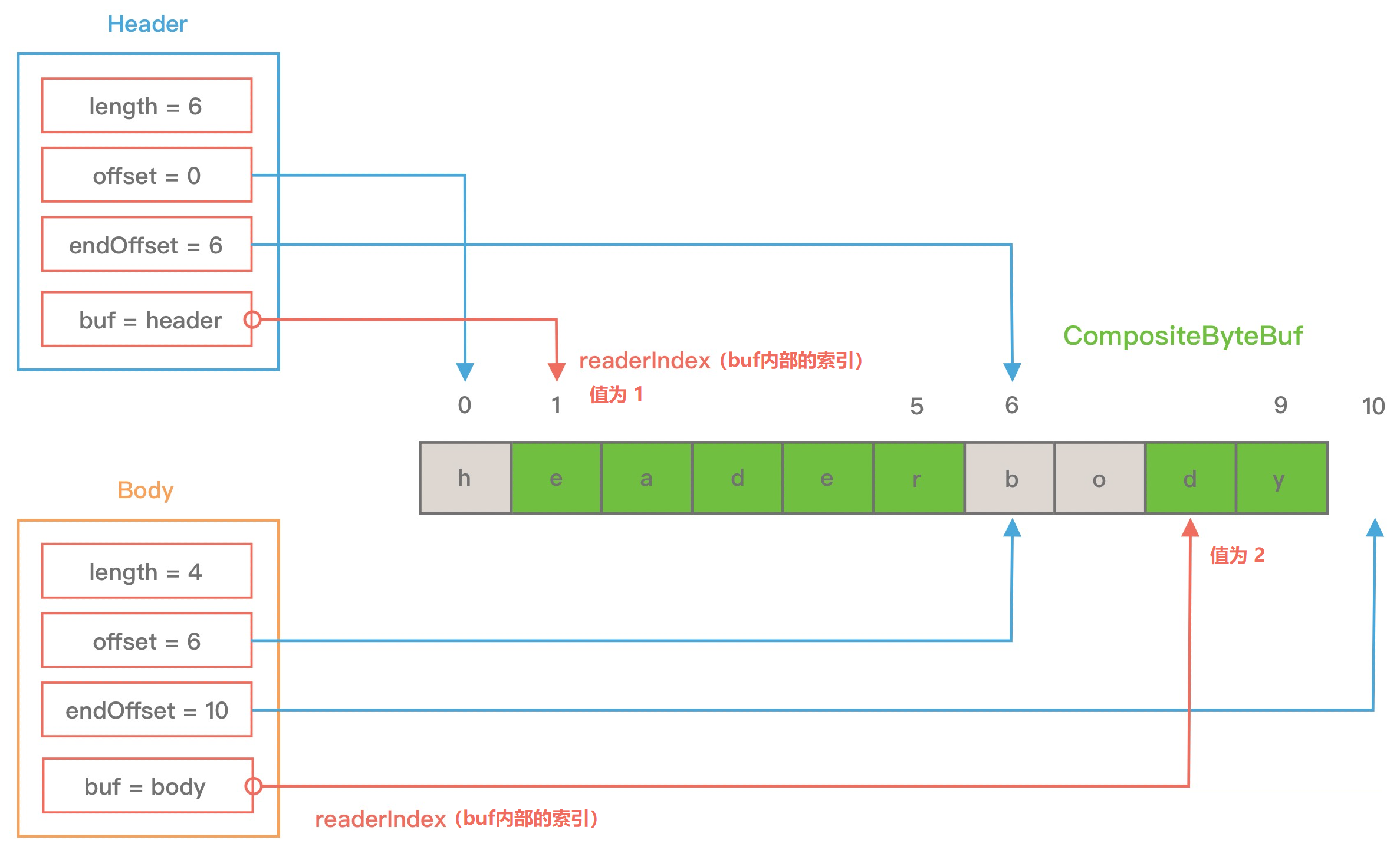
从图中可以看出, header 和 body 分别对应两个 ByteBuf, 假设 ByteBuf 的内容分别为 “header” 和 “body”, 那么 header ByteBuf 中 offset ~ endOffset 为 0 ~ 6, body ByteBuf 对应的 offset ~ endOffset 为 6 ~ 10. 由此可见, Component 中的 offset 和 endOffset 可以表示当前 ByteBuf 可以读取的范围, 通过 offset 和 endOffset 可以将每一个 Component 所对应的 ByteBuf 连接起来, 形成一个逻辑整体.
此外 Component 中 srcAdjustment 和 adjustment 表示这个 CompositeByteBuf 相对于 srcBuf 的起始索引. 初始 adjustment = readIndex - offset, 这样通过 ByteBuf 在 CompositeByteBuf 的起始索引就可以直接定位到 Component 中 ByteBuf 的读索引位置. 例如: 当 header ByteBuf 读取 1 个字节, body ByteBuf 读取 2 个字节, 此时每个 Component 的属性如下图所示.
Unpooled.wrappedBuffer 操作
介绍完 CompositeByteBuf 之后, 再来理解 Unpooled.wrappedBuffer 操作就非常容易了.
Unpooled.wrappedBuffer 同时也是创建 CompositeByteBuf 对象的另一种推荐做法.
Unpooled 提供了一系列用于包装数据源的 wrappedBuffer 方法:
1 | // Creates a new big-endian buffer which wraps the specified array. A modification on the specified array's content will be visible to the returned buffer. |
Unpooled.wrappedBuffer 方法可以将不同的数据源的一个或者多个数据包装成一个大的 ByteBuf 对象, 其中数据源的类型包括 byte[]、ByteBuf、ByteBuffer. 包装的过程中不会发生数据拷贝操作, 包装后生成的 ByteBuf 对象和原始 ByteBuf 对象是共享底层的 byte 数组.
ByteBuf.slice 操作
ByteBuf.slice 和 Unpooled.wrappedBuffer 的逻辑正好相反, ByteBuf.slice 是将一个 ByteBuf 对象切分成多个共享同一个底层存储的 ByteBuf 对象.
ByteBuf 提供了两个 slice 切分方法:
1 | // Returns a slice of this buffer's readable bytes. Modifying the content of the returned buffer or this buffer affects each other's content while they maintain separate indexes and marks. This method is identical to buf.slice(buf.readerIndex(), buf.readableBytes()). This method does not modify readerIndex or writerIndex of this buffer. |
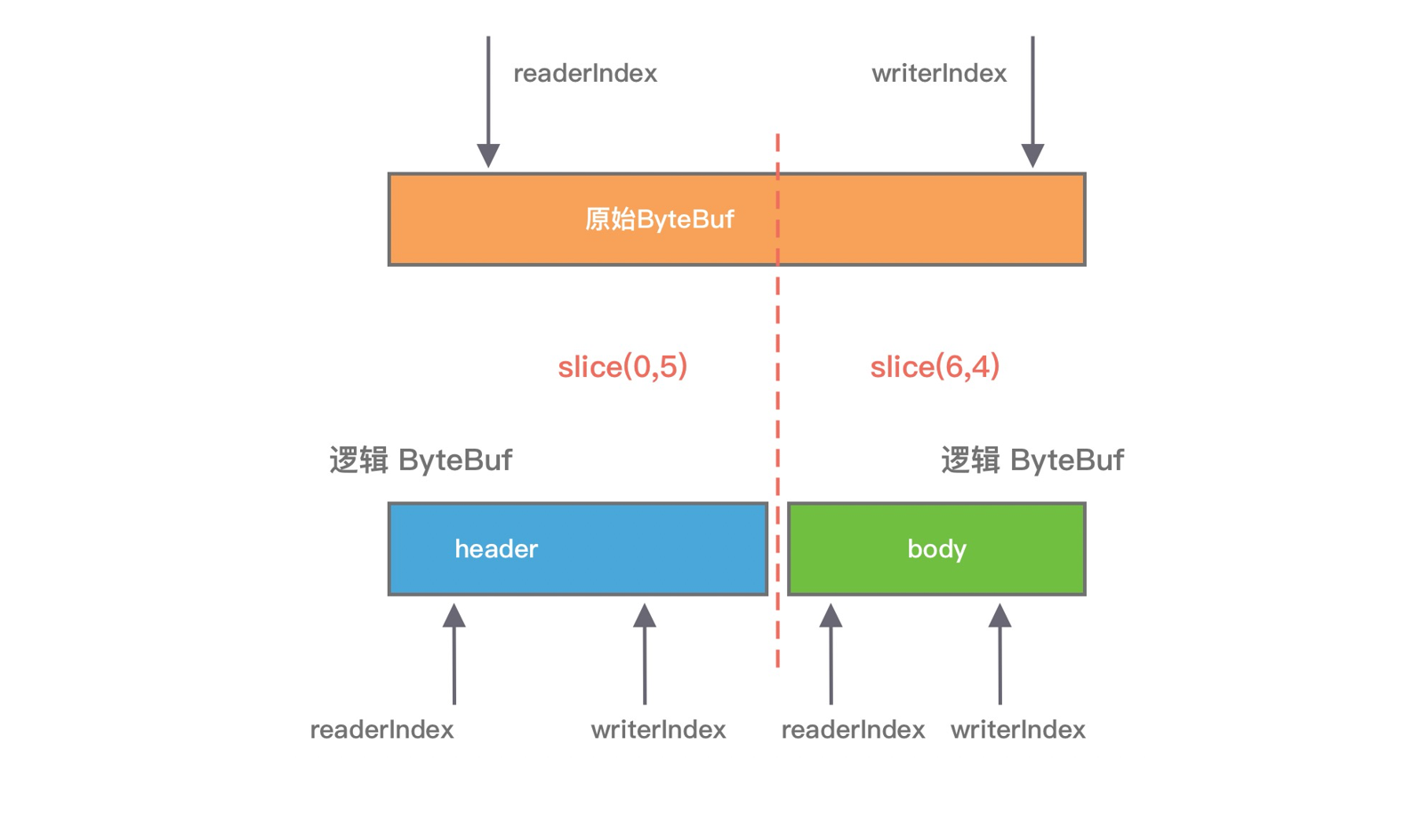
假设我们已经有一份完整的 HTTP 数据, 可以通过 slice 方法切分获得 header 和 body 两个 ByteBuf 对象, 对应的内容分别为 “header” 和 “body”, 实现方式如下:
1 | ByteBuf httpBuf = ... |
通过 slice 切分后都会返回一个新的 ByteBuf 对象, 而且新的对象有自己独立的 readerIndex、writerIndex 索引, 如下图所示. 由于新的 ByteBuf 对象与原始的 ByteBuf 对象数据是共享的, 所以通过新的 ByteBuf 对象进行数据操作也会对原始 ByteBuf 对象生效.
文件传输 FileRegion
在 Netty 源码的 example 包中, 提供了 FileRegion 的使用示例, 以下代码片段摘自 FileServerHandler.java
1 |
|
从 FileRegion 的使用示例可以看出, Netty 使用 FileRegion 实现文件传输的零拷贝. FileRegion 的默认实现类是 DefaultFileRegion, 通过 DefaultFileRegion 将文件内容写入到 NioSocketChannel. 那么 FileRegion 是如何实现零拷贝的呢? 我们通过源码看看 FileRegion 到底使用了什么黑科技.
1 | public class DefaultFileRegion extends AbstractReferenceCounted implements FileRegion { |
从源码可以看出, FileRegion 其实就是对 FileChannel 的包装, 并没有什么特殊操作, 底层使用的是 JDK NIO 中的 FileChannel#transferTo() 方法实现文件传输, 所以 FileRegion 是操作系统级别的零拷贝, 对于传输大文件会很有帮助.
可以看出 Netty 对于 ByteBuf 做了更多精进的设计和优化.
netty 泄漏检测
Netty 统一管理内存在减轻 GC 的压力, 避免向 OS 频繁申请和释放内存的同时, 也带来一个坏处, 就是开发者使用完毕后, 必须及时释放掉资源, 否则会导致内存泄漏.
自己管理内存会带来更好的性能, 但是也增大了内存泄漏的可能性. 为了尽量避免内存泄漏, Netty 提供了 ResourceLeakDetector 资源泄漏探测器, 它会对分配的资源进行检测, 一旦发生泄漏, 它会进行报告, 让开发者能及时发现并进行修正.
ResourceLeakDetector 简介
当 Channel 有数据可读时, Netty 默认会通过 PooledByteBufAllocator 创建一个 ByteBuf, 并将数据写入到 ByteBuf, 然后通过 Pipeline 将 ChannelRead 事件传播出去. 如下, 是一个简单的使用示例:
1 | public class LeakDemo { |
运行程序, 控制台会报告资源泄漏的情况, 输出如下:
1 | 161610.021 pid:test_project thread:main ERROR [ResourceLeakDetector] LEAK: ByteBuf.release() was not called before it's garbage-collected. See https://netty.io/wiki/reference-counted-objects.html for more information. |
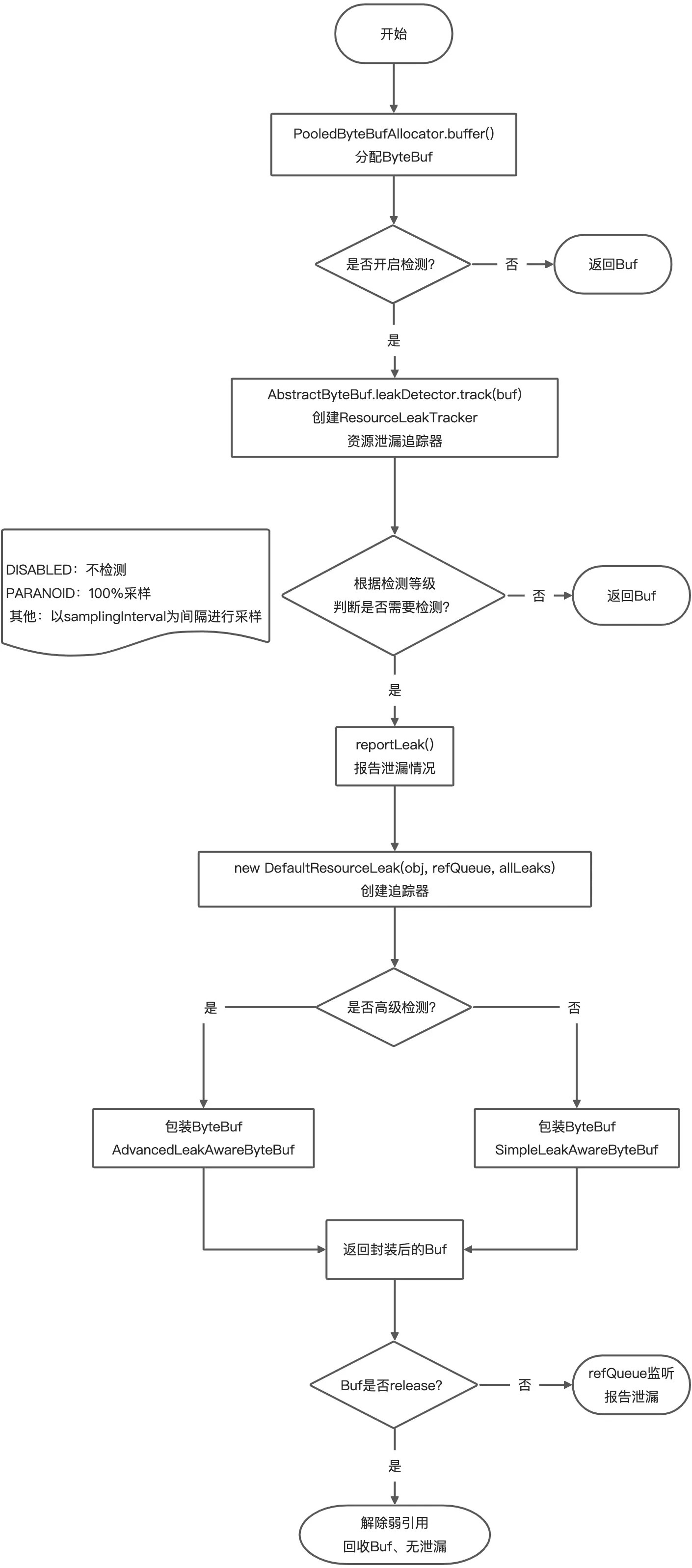
ResourceLeakDetector 大致工作流程
检测等级
Netty 提供了 4 个检测等级, 不同的级别采样率不同, 开销也不一样, 用户可以根据实际情况选择合适的级别
| 检测等级 | 说明 |
|---|---|
| DISABLED | 禁用检测 |
| SIMPLE | 简单检测, 少量的采样, 不报告泄漏的位置 |
| ADVANCED | 高级检测, 少量的采样, 会报告泄漏的位置 |
| PARANOID | 偏执检测, 100%采样, 会报告泄漏的位置 |
通过设置 JVM 参数 -Dio.netty.leakDetection.level=PARANOID 来调整检测等级.
源码分析
分析一下源码, 看看 Netty 是如何检测资源泄漏并及时报告用户的. 在看 ResourceLeakDetector 前, 先了解几个比较重要的类.
源码基于 netty 4.1.79.Final 版本分析
DefaultResourceLeak
DefaultResourceLeak 是默认的资源泄漏追踪器, 它继承自 WeakReference, 它会为追踪对象建立一个弱引用连接, 当追踪对象被 GC 回收后, JVM 会将 WeakReference 加入到 refQueue, 通过 refQueue 就能判断是否存在资源泄漏了.
先看它的属性:
1 | /* |
再看构造函数:
1 | /** |
DefaultResourceLeak 的创建过程还是比较简单的, 重要的是 TraceRecord 的创建, 它才是记录追踪堆栈的功能类.
TraceRecord
TraceRecord 记录着追踪对象访问的堆栈轨迹, 它继承自 Throwable, 这样它就可以通过调用 Throwable.getStackTrace() 获取堆栈跟踪的元素数组了.
TraceRecord 类本身不复杂, 重要的是它的 toString() 方法, 它会把追踪对象的访问堆栈信息给构建出来.
属性如下:
1 | // 额外的提示信息 |
构造函数:
1 | /** |
toString()方法, 用来构建追踪对象的堆栈信息:
1 | // 构建跟踪的堆栈信息 |
ResourceLeakDetector
回到 ResourceLeakDetector, 以 PooledByteBufAllocator.newDirectBuffer() 申请池化的直接内存为例, 它创建完 ByteBuf 后不会立即返回, 它需要在 ByteBuf 发生泄漏时感知到, 因此需要对 ByteBuf 做一个包装.
1 |
|
toLeakAwareBuffer() 会判断是简单检测还是高级检测, 返回不同的包装类, 这个包装类后面会说.
1 | // 尝试感知Buf的资源泄漏 |
AbstractByteBuf.leakDetector.track(buf) 方法比较核心, 它会返回一个 buf 的泄漏追踪器, 当 buf 被正常释放时, 包装类会自动关闭追踪器, 反之资源泄漏时, 追踪器可以感知到, 并发出报告.
1 |
|
这里用到了几个属性, 说明下:
1 | // ByteBuf被检测后, 会创建一个弱引用指向它, GC时如果ByteBuf没有强引用被回收, |
reportLeak() 的功能是报告资源的泄漏情况, 前面说过当追踪对象被 GC 回收掉后, JVM 会将 WeakReference 加入到 refQueue 中, 因此这里会遍历 refQueue, 取出泄漏对象后, 调用它的 toString() 来获取堆栈信息, reportUntracedLeak() 就很简单了, 只是通过 logger 进行输出.
1 | // 报告泄漏情况 |
DefaultResourceLeak.getReportAndClearRecords() 调用了 DefaultResourceLeak.generateReport() 构建堆栈信息, 让用户感知到资源在哪里发生了泄漏. generateReport() 也比较简单, 就是对 TraceRecord 做遍历, 拼接方法调用的堆栈信息.
1 | String getReportAndClearRecords() { |
至此, 创建资源泄漏追踪器和泄漏报告的流程就全部结束了.
简单检测和高级检测
创建完 ResourceLeakTracker 资源泄漏追踪器后, Netty 还需要将 ByteBuf 进行包装, 这里用到了 装饰器模式, 装饰类的功能有两个:
- 追踪对象被 release 后, 关闭追踪器.
- 追踪对象被访问后, 记录堆栈.
对于第二个功能点, 只有高级检测才需要, 因此 Netty 提供了两个包装类: SimpleLeakAwareByteBuf 和 AdvancedLeakAwareByteBuf, 简单检测和高级检测.
它俩的区别就是简单检测不会记录追踪对象访问的堆栈信息, 只会单纯的报告发生了泄漏, 这样的好处是开销较小, 坏处是无法确定泄漏的位置.
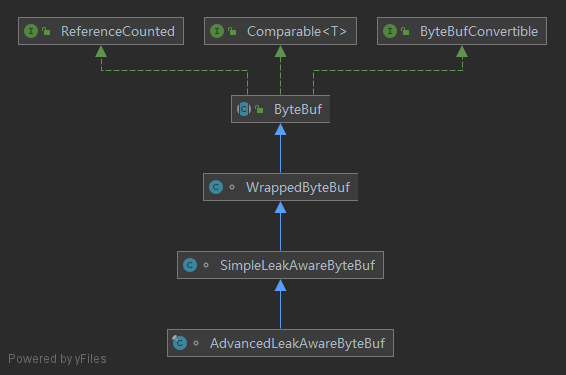
装饰类需要依赖一个原生的 ByteBuf, 所有的操作都委托给 ByteBuf 去执行, 它会在需要增强的方法前后插入一些扩展功能.
以增强后的 release() 方法示例:
1 | // SimpleLeakAwareByteBuf 中的 release 方法 |
closeLeak() 会调用 DefaultResourceLeak.close() 关闭追踪:
1 | // SimpleLeakAwareByteBuf 中的 closeLeak 方法 |
leak.record() 会调用 DefaultResourceLeak.record0() 方法记录堆栈信息, 创建一个 TraceRecord 加入到追踪记录的链表中
泄漏总结
Netty 根据 WeakReference 弱引用来判断对象是否发生内存泄漏, 通过创建一个追踪对象的装饰类来进行增强, 当追踪对象被 release 后, 自动关闭追踪器, 否则在发生泄漏时进行报告.
如果开启了资源泄漏检测, Netty 会为追踪对象创建一个泄漏追踪器 ResourceLeakTracker, ResourceLeakTracker 包含一个单向链表, 链表由一系列 TraceRecord 组成, 它代表的是对象访问的堆栈记录, 如果发生了资源泄漏, Netty 会根据这个链表构建资源泄漏的位置信息并写入日志.
Netty 提供了两种检测机制, 分别是简单的和高级的, 对于高级检测, Netty 还会记录追踪对象的访问堆栈信息, 在报告时可以快速定位到资源泄漏的具体位置, 缺点是这会带来较大的额外开销, 不建议在线上使用.
jemalloc 基本原理
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器. 它是一个通用的 malloc 实现, 侧重于减少内存碎片和提升高并发场景下内存的分配效率, 其目标是能够替代 malloc. jemalloc 应用十分广泛, 在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用. 具体细节可以参考 Jason Evans 发表的论文 《A Scalable Concurrent malloc Implementation for FreeBSD》
内存分配器目标(memory allocator)
- 减少内存碎片, 包括内部碎片和外部碎片
- 提高性能
- 提高安全性
jemalloc, ptmalloc, tcmalloc 对比
- ptmalloc 是基于 glibc 实现的内存分配器, 它是一个标准实现, 所以兼容性较好. pt 表示 per thread 的意思. 当然 ptmalloc 确实在多线程的性能优化上下了很多功夫. 由于过于考虑性能问题, 多线程之间内存无法实现共享, 只能每个线程都独立使用各自的内存, 所以在内存开销上是有很大浪费的.
- tcmalloc 出身于 Google, 全称是 thread-caching malloc, 所以 tcmalloc 最大的特点是带有线程缓存, tcmalloc 非常出名, 目前在 Chrome、Safari 等知名产品中都有所应有. tcmalloc 为每个线程分配了一个局部缓存, 对于小对象的分配, 可以直接由线程局部缓存来完成, 对于大对象的分配场景, tcmalloc 尝试采用自旋锁来减少多线程的锁竞争问题.
- jemalloc 借鉴了 tcmalloc 优秀的设计思路, 所以在架构设计方面两者有很多相似之处, 同样都包含 thread cache 的特性. 但是 jemalloc 在设计上比 ptmalloc 和 tcmalloc 都要复杂, jemalloc 将内存分配粒度划分为 Small、Large、Huge 三个分类, 并记录了很多 meta 数据, 所以在空间占用上要略多于 tcmalloc, 不过在大内存分配的场景, jemalloc 的内存碎片要少于 tcmalloc. jemalloc 内部采用红黑树管理内存块和分页, Huge 对象通过红黑树查找索引数据可以控制在指数级时间.
虽然几个内存分配器的侧重点不同, 但是它们的核心目标是一致的:
- 高效的内存分配和回收, 提升单线程或者多线程场景下的性能.
- 减少内存碎片, 包括内部碎片和外部碎片, 提高内存的有效利用率.
内存碎片: Linux 中物理内存会被划分成若干个 4K 大小的内存页 Page, 物理内存的分配和回收都是基于 Page 完成的, Page 内产生的内存碎片称为内部碎片, Page 之间产生的内存碎片称为外部碎片.
常用内存分配器算法
最常用的内存分配器算法有:
- 动态内存分配
- 伙伴算法
- Slab 算法
动态内存分配
动态内存分配 (Dynamic memory allocation, 简称 DMA) 又称为堆内存分配, 操作系统根据程序运行过程中的需求即时分配内存, 且分配的内存大小就是程序需求的大小. 在大部分场景下, 只有在程序运行的时候才知道所需要分配的内存大小, 如果提前分配可能会分配的大小无法把控, 分配太大会浪费空间, 分配太小会无法使用.
DMA 是从一整块内存中按需分配, 对于分配出的内存会记录元数据, 同时还会使用空闲分区链维护空闲内存, 便于在内存分配时查找可用的空闲分区, 常用的有三种查找策略:
- ⾸次适应算法 (first fit)
- 循环首次适应算法 (next fit)
- 最佳适应算法 (best fit)
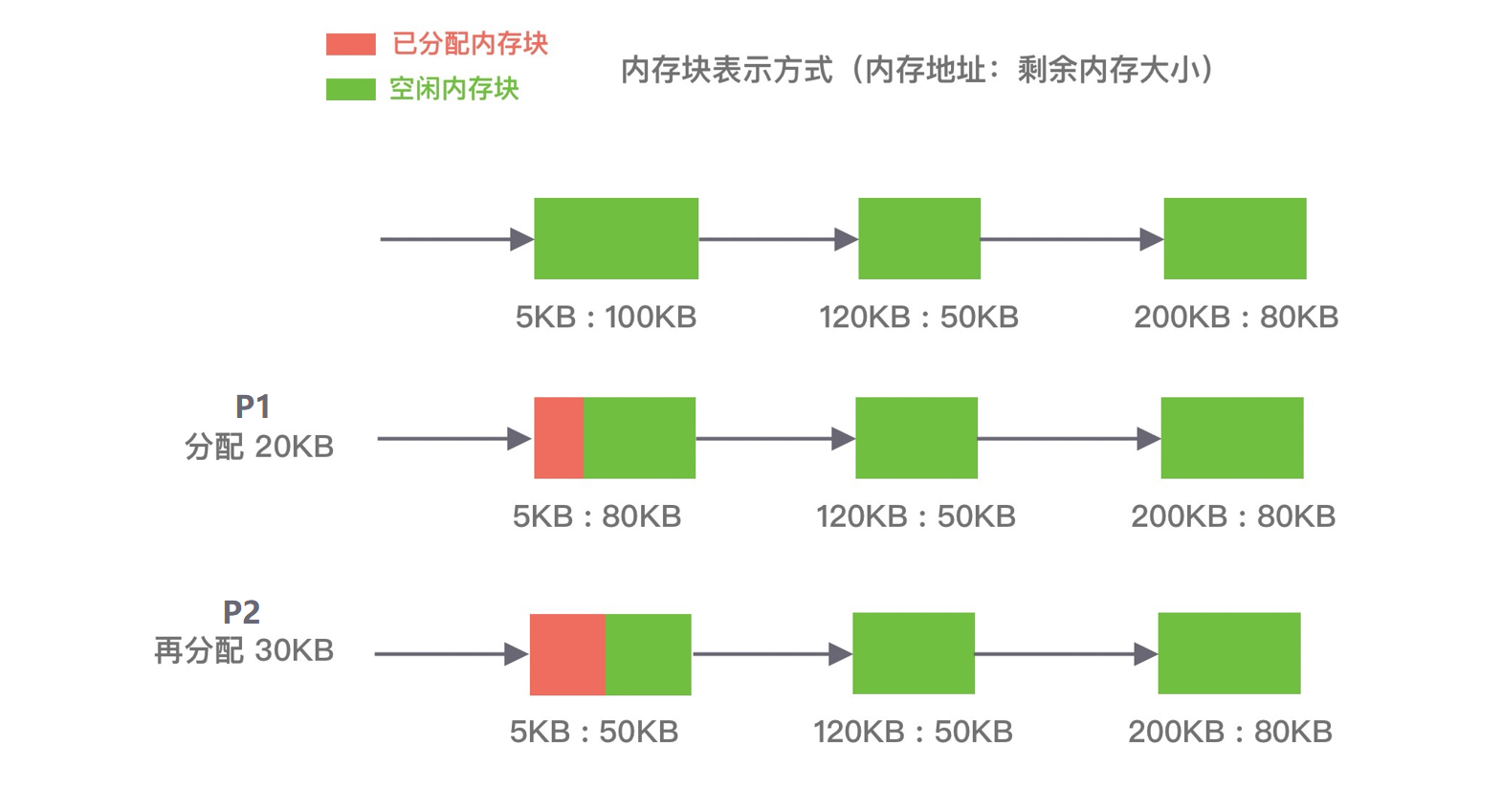
⾸次适应算法 (first fit)
空闲分区链以地址递增的顺序将空闲分区以双向链表的形式连接在一起, 从空闲分区链中找到第一个满足分配条件的空闲分区, 然后从空闲分区中划分出一块可用内存给请求进程, 剩余的空闲分区仍然保留在空闲分区链中.
如下图所示, P1 和 P2 的请求可以在内存块 A 中完成分配.
但是该算法每次都从低地址开始查找, 造成低地址部分会不断被分配, 同时也会产生很多小的空闲分区.
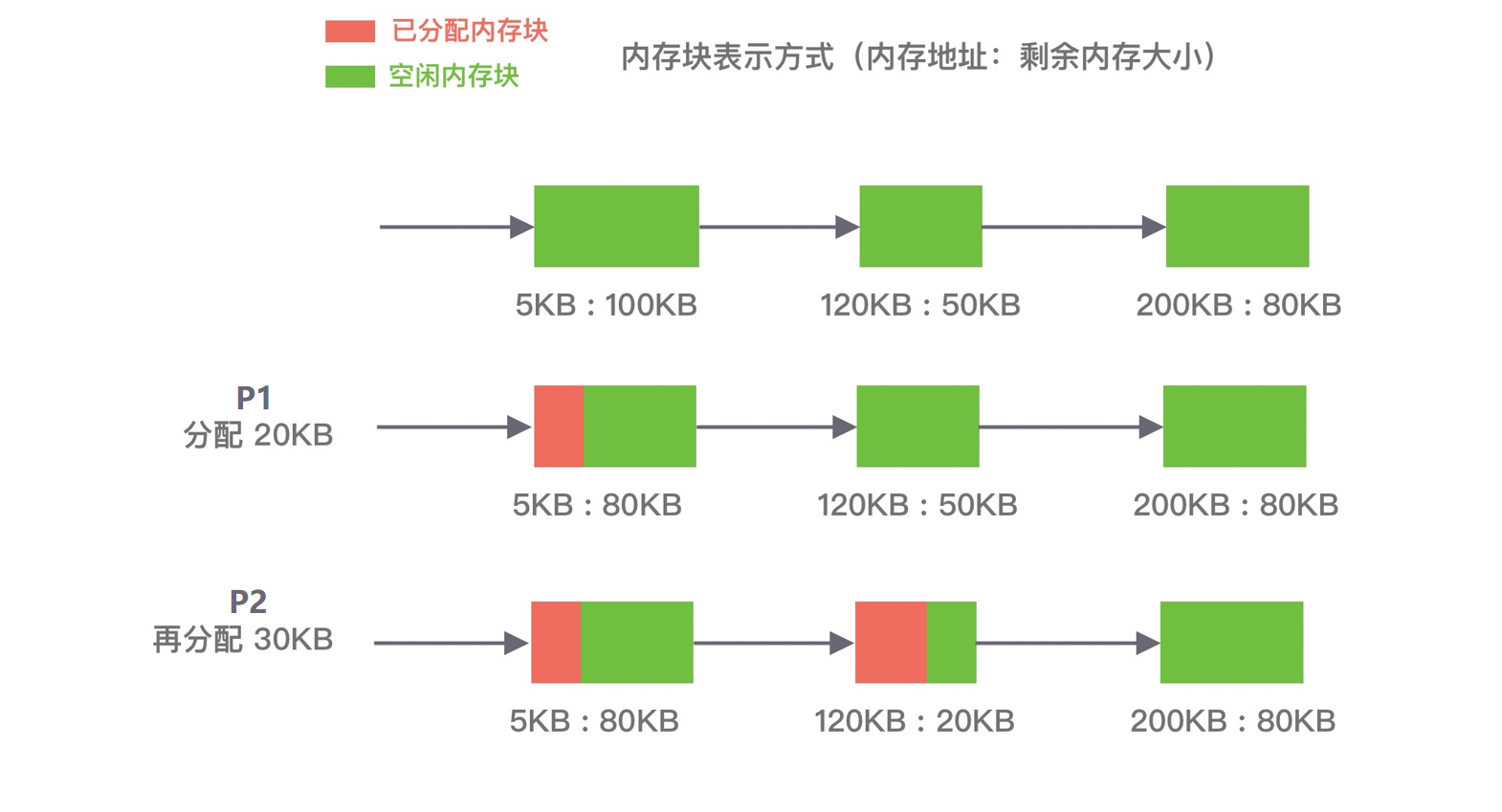
循环首次适应算法 (next fit)
该算法是由首次适应算法的变种, 循环首次适应算法不再是每次从链表的开始进行查找, 而是从上次找到的空闲分区的下⼀个空闲分区开始查找.
如下图所示, P1 请求在内存块 A 完成分配, 然后再为 P2 分配内存时, 是直接继续向下寻找可用分区, 最终在 B 内存块中完成分配.
该算法相比⾸次适应算法空闲分区的分布更加均匀, 而且查找的效率有所提升, 但是正因为如此会造成空闲分区链中大的空闲分区会越来越少.
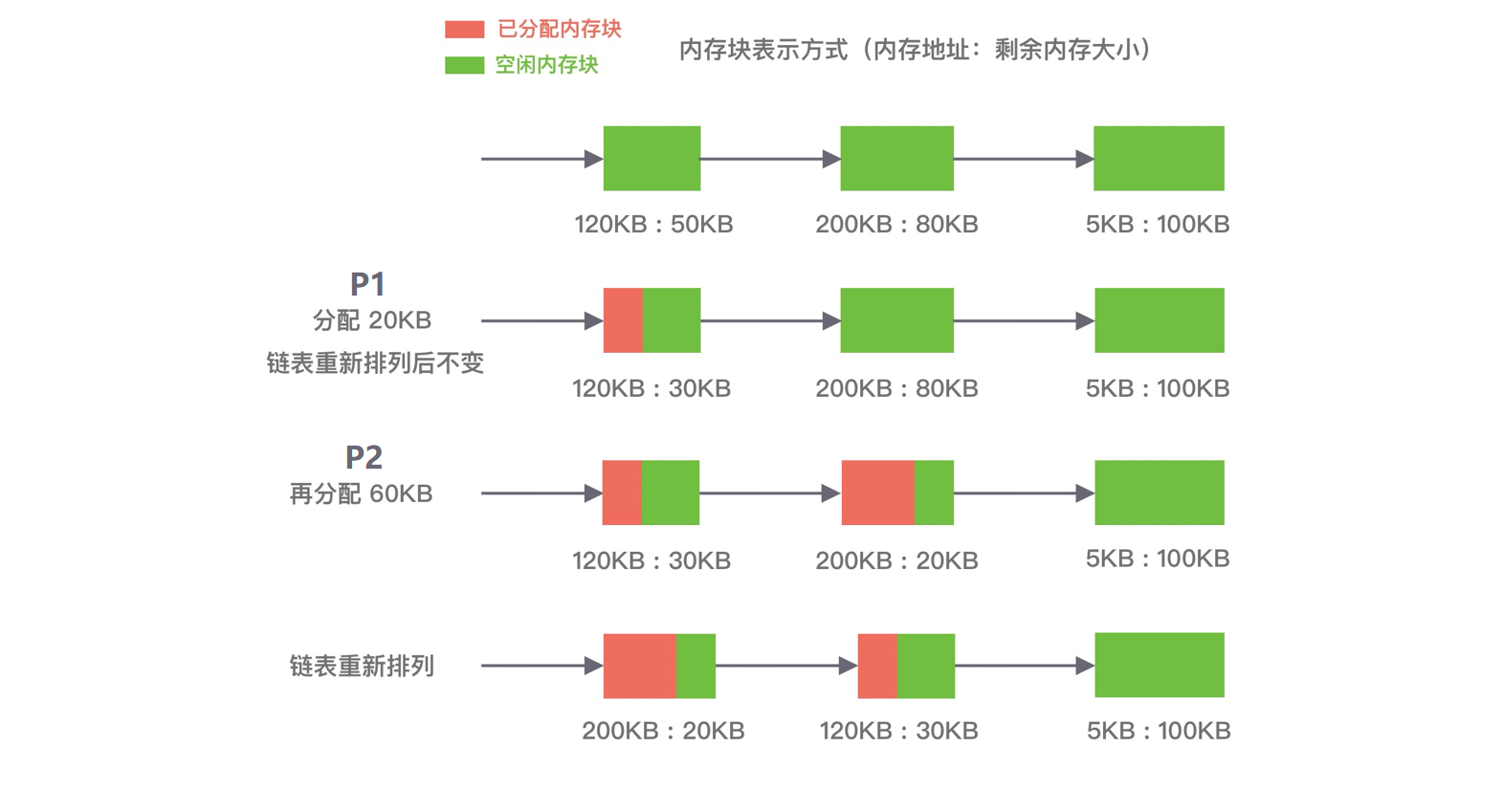
最佳适应算法 (best fit)
空闲分区链以空闲分区大小递增的顺序将空闲分区以双向链表的形式连接在一起, 每次从空闲分区链的开头进行查找, 这样第一个满足分配条件的空间分区就是最优解.
如下图所示, 在 A 内存块分配完 P1 请求后, 空闲分区链重新按分区大小进行排序, 再为 P2 请求查找满足条件的空闲分区.
该算法的空间利用率更高, 但同样也会留下很多较难利用的小空闲分区, 由于每次分配完需要重新排序, 所以会有造成性能损耗.
伙伴算法
伙伴算法是一种非常经典的内存分配算法, 它采用了分离适配的设计思想, 将物理内存按照 2 的次幂进行划分, 内存分配时也是按照 2 的次幂大小进行按需分配, 例如 4KB、 8KB、16KB 等. 假设我们请求分配的内存大小为 10KB, 那么会按照 16KB 分配.
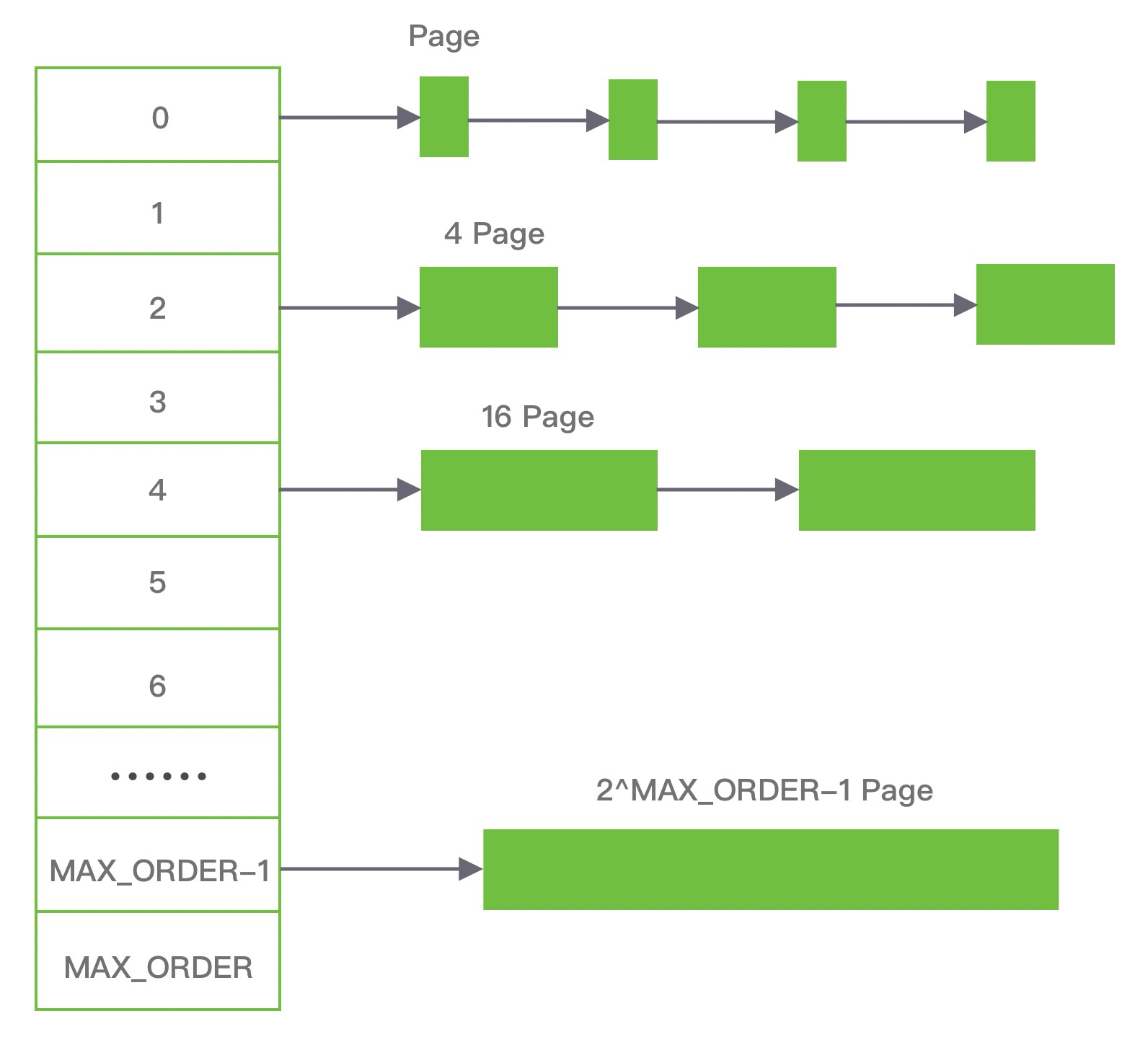
伙伴算法把内存划分为 11 组不同的 2 次幂大小的内存块集合, 每组内存块集合都用双向链表连接. 链表中每个节点的内存块大小分别为 1、2、4、8、16、32、64、128、256、512 和 1024 个连续的 Page (每个 Page 4KB), 例如第一组链表的节点为 2^0 个连续 Page, 第二组链表的节点为 2^1 个连续 Page, 以此类推.
假设我们需要分配 10K 大小的内存块, 看下伙伴算法的具体分配过程:
- 首先需要找到存储 2^4 连续 Page 所对应的链表, 即数组下标为 4;
- 查找 2^4 链表中是否有空闲的内存块, 如果有则分配成功;
- 如果 2^4 链表不存在空闲的内存块, 则继续沿数组向上查找, 即定位到数组下标为 5 的链表, 链表中每个节点存储 2^5 的连续 Page;
- 如果 2^5 链表中存在空闲的内存块, 则取出该内存块并将它分割为 2 个 2^4 大小的内存块, 其中一块分配给进程使用, 剩余的一块链接到 2^4 链表中.
释放内存时候伙伴算法又会发生什么行为呢?
- 当进程使用完内存归还时, 需要检查其伙伴块的内存是否释放, 所谓伙伴块是不仅大小相同, 而且两个块的地址是连续的, 其中低地址的内存块起始地址必须为 2 的整数次幂.
- 如果伙伴块是空闲的, 那么就会将两个内存块合并成更大的块, 然后重复执行上述伙伴块的检查机制.
- 直至伙伴块是非空闲状态, 那么就会将该内存块按照实际大小归还到对应的链表中.
频繁的合并会造成 CPU 浪费, 所以并不是每次释放都会触发合并操作, 当链表中的内存块个数小于某个阈值时, 并不会触发合并操作.
由此可见, 伙伴算法有效地减少了外部碎片, 但是有可能会造成非常严重的内部碎片, 最严重的情况会带来 50% 的内存碎片.
Slab 算法
因为伙伴算法都是以 Page 为最小管理单位, 在小内存的分配场景, 伙伴算法并不适用, 如果每次都分配一个 Page 岂不是非常浪费内存, 因此 Slab 算法应运而生了. Slab 算法在伙伴算法的基础上, 对小内存的场景专门做了优化, 采用了内存池的方案, 解决内部碎片问题.
Linux 内核使用的就是 Slab 算法, 因为内核需要频繁地分配小内存, 所以 Slab 算法提供了一种高速缓存机制, 使用缓存存储内核对象, 当内核需要分配内存时, 基本上可以通过缓存中获取. 此外 Slab 算法还可以支持通用对象的初始化操作, 避免对象重复初始化的开销. 下图是 Slab 算法的结构图, Slab 算法实现起来非常复杂, 本文只做一个简单的了解.
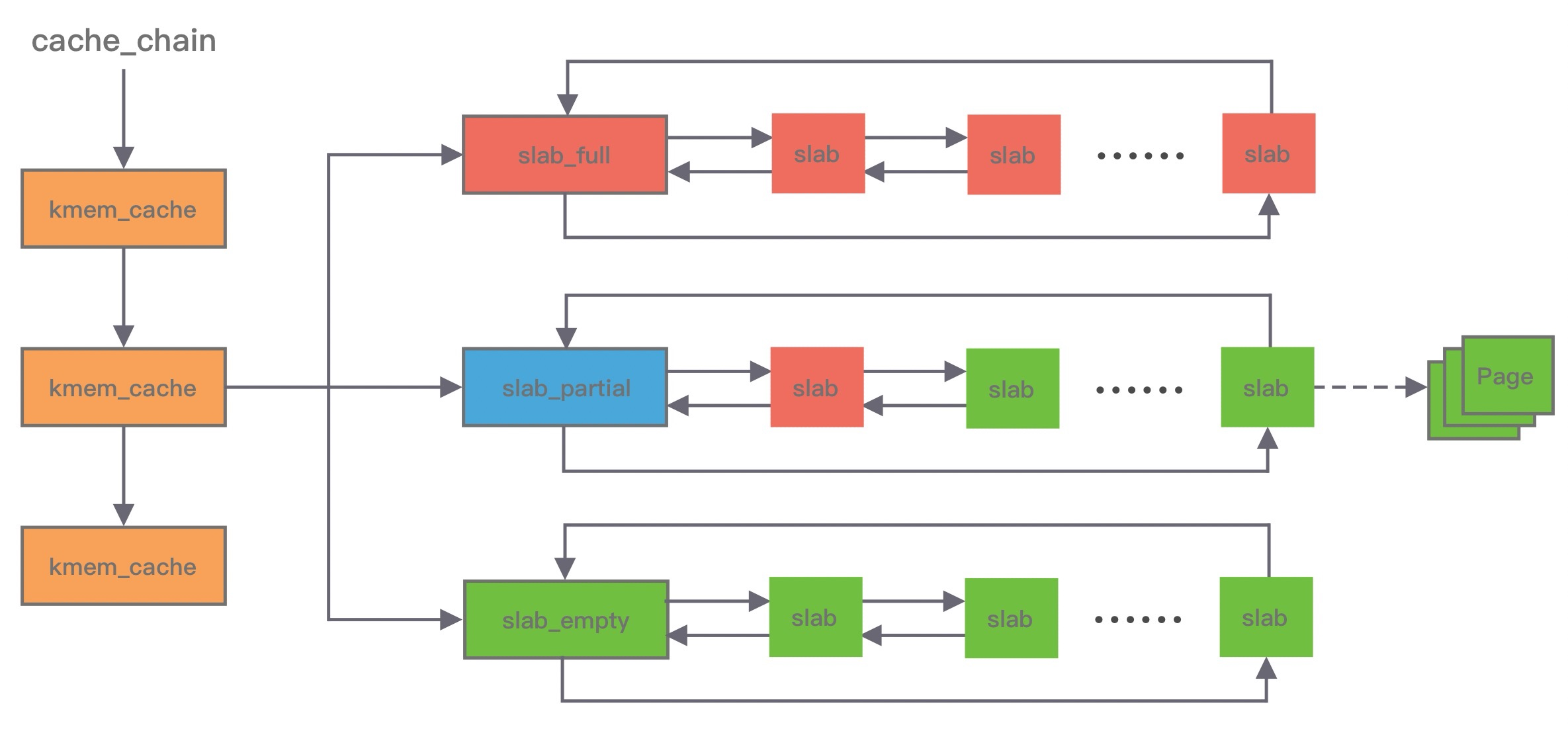
在 Slab 算法中维护着大小不同的 Slab 集合, 在最顶层是 cache_chain, cache_chain 中维护着一组 kmem_cache 引用, kmem_cache 负责管理一块固定大小的对象池. 通常会提前分配一块内存, 然后将这块内存划分为大小相同的 slot, 不会对内存块再进行合并, 同时使用位图 bitmap 记录每个 slot 的使用情况.
kmem_cache 中包含三个 Slab 链表: 完全分配使用 slab_full、部分分配使用 slab_partial 和完全空闲 slabs_empty, 这三个链表负责内存的分配和释放. 每个链表中维护的 Slab 都是一个或多个连续 Page, 每个 Slab 被分配多个对象进行存储. Slab 算法是基于对象进行内存管理的, 它把相同类型的对象分为一类. 当分配内存时, 从 Slab 链表中划分相应的内存单元; 当释放内存时, Slab 算法并不会丢弃已经分配的对象, 而是将它保存在缓存中, 当下次再为对象分配内存时, 直接会使用最近释放的内存块.
单个 Slab 可以在不同的链表之间移动, 例如当一个 Slab 被分配完, 就会从 slab_partial 移动到 slabs_full, 当一个 Slab 中有对象被释放后, 就会从 slab_full 再次回到 slab_partial, 所有对象都被释放完的话, 就会从 slab_partial 移动到 slab_empty.
至此, 三种最常用的内存分配算法已经介绍完了, 优秀的内存分配算法都是在性能和内存利用率之间寻找平衡点, jemalloc 就是非常典型的例子.
jemalloc 架构设计
jemalloc 有五个重要的数据结构: arena, bin, chunk, run, tcache
这五个数据结构可以分为三类:
- 物理布局相关: chunk, run
- 核心管理相关: arena, bin
- 线程本地缓存: tcache
5 个数据结构含义:
- chunk: 负责管理用户内存块的数据结构
- chunk 以 Page 为单位管理内存, 默认大小是 4M, 即 1024 个连续 Page
- jemalloc 向操作系统获取内存是以 chunk 为单位的
- 每个 chunk 可被用于多次小内存的申请, 但是在大内存分配的场景下只能分配一次
- run: 是 chunk 中的一块内存区域, jemalloc 从操作系统获取一个 chunk 的内存后, 会将 chunk 切分成 run 进行管理
- 每个 bin 管理相同类型的 run, 最终通过操作 run 完成内存分配
- run 结构具体的大小由不同的 bin 决定, 例如 8 字节的 bin 对应的 run 只有一个 Page, 可以从中选取 8 字节的块进行分配
- arena: jemalloc 的核心管理器, 多线程环境下默认数量为处理器核数 4 倍
- arena 管理着 jemalloc 的 chunk, 包括释放掉的 chunk 以及正在使用的 chunk, 对于正在使用的 chunk, arena 会将其切分成 run 进行管理
- bin: jemalloc 核心管理器的子管理器, 即 arena 的次级管理器
- 负责 small bin 的分配, 从 arena 申请 run, 并将 run 划分成 region 进行实际的 small 分配
- 每个 bin 管理的内存大小是按分类依次递增. 因为 jemalloc 中小内存的分配是基于 Slab 算法完成的, 所以会产生不同类别的内存块
- tcache: 从属于某个线程的缓存分配器, 是每个线程私有的缓存
- tcache 按照策略从 arena/bin 中获取一定数量 的
small bin及部分 large放在本地缓存, 线程的大部分申请都是从 tcache 中获取, 大部分释放都是放回 tcache, tcache 也会按照某种策略将部分缓存放回 arena/bin
- tcache 按照策略从 arena/bin 中获取一定数量 的
jemalloc 架构图:
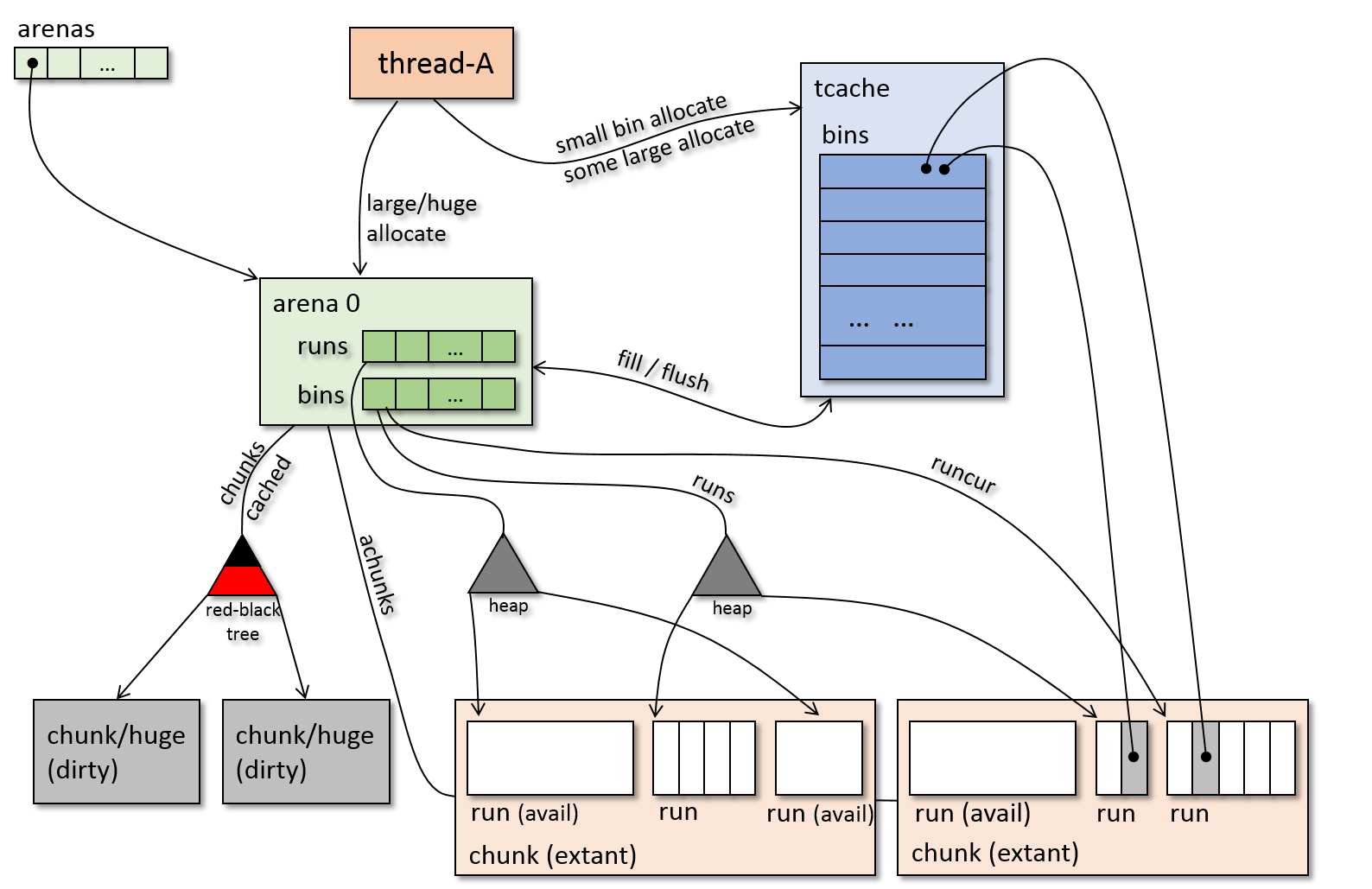
上图体现了 jemalloc 中的一些重要数据结构和重要工作流程:
- 每个线程会和 2 个 arena 绑定(为了方便, 图中画了一个), 一个用于 application 内存分配, 一个用于 internal 内存分配, 不过目前 internal 数据 主要分配在 base 和 arena 0 中, 并没有用到 internal 绑定的 arena
- 每个 arena 会被多个线程使用, 这个取决于线程的数量和 CPU 核数
- 每个线程有一个自己的 tcache, tcache 中会缓存所有类型的 small bin 和 少数几类 large, 其并不是真的缓存, 而是保存指向内存的指针, 被缓存的内存会在 run 或者 chunk 中标记为已经分配
- 线程申请属于 tcache 范围内的内存时, 首先从 tcache 中获取, 如果 tcache 中有, 则直接获取, 没有的话, 如果是 small, 则 tcache 从 arena 中获取内存来填充, 再分配 给线程, 如果是 large, 则 线程 重新向 arena 申请
- tcache 会根据策略, 选择时机向 arena 释放内存(flush), 或者从 arena 获取内存填充 bin (fill)
- 线程申请不属于 tcache 的 large 时, 或者申请 huge 时, 直接向 arena 申请
- arena 使用红黑树管理脏的 chunk/huge (被释放的 chunk/huge), 实际 arena 使用多棵 红黑树管理被释放的 chunk/huge, 用于不同的用途, 这里只画了一颗
- arena 对可用的 runs 进行分组管理, 每一组使用 堆 维护
- arena 中对多组 bin 管理, bin 内部使用 堆 对自己的 run 管理
- arena 中的 achunks 使用 链表 维护正在使用的 chunk
netty 线程模型
Java NIO 新连接处理流程
- 通过 I/O 多路复用器——Selector 检测客户端新连接
对应到 Netty, 新连接通过服务端的 NioServerSocketChannel (底层封装的 JDK 的 ServerSocketChannel) 绑定的 I/O 多路复用器 (由 NioEventLoop 线程驱动) 轮询 OP_ACCEPT(=16)事件 - 轮询到新连接, 就创建客户端的 Channel
对应到 Netty 就是 NioSocketChannel (底层封装 JDK 的 SocketChannel) - 为新连接分配绑定新的 Selector
对应到 Netty, 就是通过线程选择器, 从它的第二个线程池——worker 线程池中挑选一个 NIO 线, 在这个线程中去执行将 JDK 的 SocketChannel 注册到新的 Selector 的流程, 将 Netty 封装的 NioSocketChannel 作为附加对象也绑定到该 Selector - 向客户端 Channel 绑定的 Selector 注册 I/O 读、或者写事件
对应到 Netty, 就是默认注册读事件, 因为 Netty 的设计理念是读优先. 以后本条 Channel 的读写事件就由 worker 线程池中的 NIO 线程管理
Netty 服务端创建的 boss 和 worker 就是两个线程池, 对于一个服务器的端口, bossGroup 里只会启动一个 NIO 线程用来处理该端口上的客户端新连接的检测和接入流程
NioEventLoopGroup 和线程池对应, NioEventLoop 实例和 NIO 线程对应, 一个 EventLoop 实例将由一个永远都不会改变的 Thread 驱动其内部的 run 方法 (和 Runnable 的 run 不是一个)
netty reactor 架构
根据 Reactor 的数量和处理资源池线程的数量不同, 有 3 种典型的实现:
- 单 Reactor 单线程
- 单 Reactor 多线程
- 主从 Reactor 多线程
Netty 主要基于 主从 Reactor 多线程模型做了一定的 改进, 其中主从 Reactor 多线程模型 有多个 Reactor
reactor 设计思想
I/O 复用结合线程池, 就是 Reactor 模式基本设计思想
基于 I/O 复用模型: 多个连接共用一个阻塞对象, 应用程序只需要在一个阻塞对象等待, 无需阻塞等待所有连接. 当某个连接有新的数据可以处理时, 操作系统通知应用程序, 线程从阻塞状态返回, 开始进行业务处理
基于线程池复用线程资源: 不必再为每个连接创建线程, 将连接完成后的业务处理任务分配给线程进行处理, 一个线程可以处理多个连接的业务.
Reactor 对应的叫法:
- 反应器模式
- 分发者模式 (Dispatcher)
- 通知者模式 (notifier)
reactor 处理流程:
- 一个或多个请求, 同时传递给 服务处理器(基于事件驱动);
- 服务器端程序处理传入的多个请求, 并将它们同步分派到相应的处理线程, 因此 Reactor 模式也叫 Dispatcher 模式;
- Reactor 模式使用 IO 复用 监听事件, 收到事件后, 分发给某个线程(进程), 这点就是网络服务器高并发处理关键.
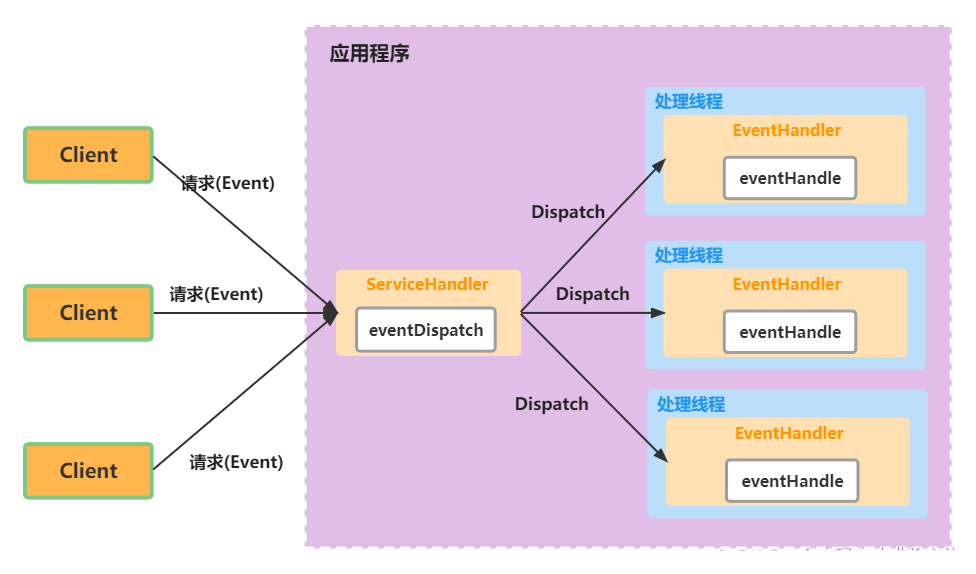
reactor 核心组成
- Reactor: 负责监听和分配事件, 将 I/O 事件分派给对应的 Handler. 新的事件包含连接建立就绪、读就绪、写就绪等
- Acceptor: 处理客户端新连接, 并分派请求到处理器链中
- Handler: 将自身与事件绑定, 执行非阻塞读/写任务, 完成 channel 的读入, 完成处理业务逻辑后, 负责将结果写出 channel. 可用资源池来管理
单 Reactor 单线程
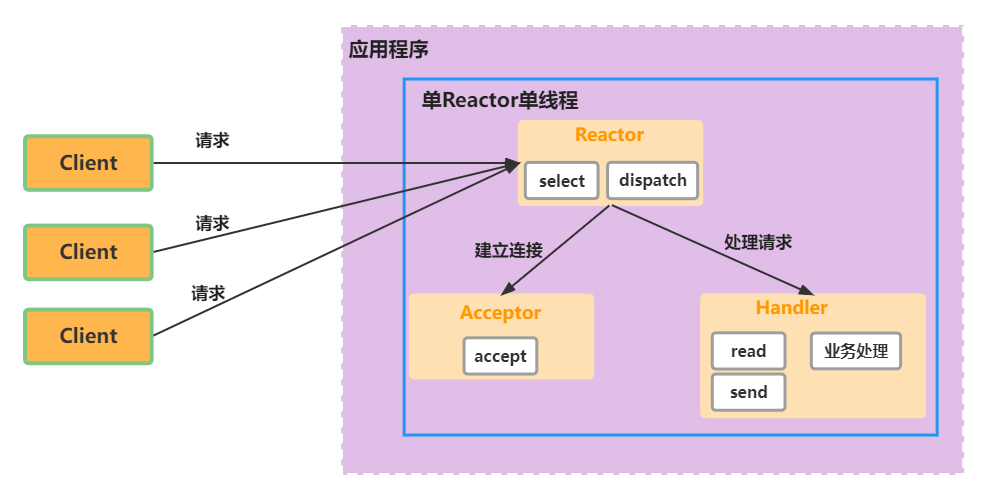
- Select 是前面 I/O 复用模型介绍的标准网络编程 API, 可以实现应用程序通过一个阻塞对象监听多路连接请求
- Reactor 对象通过 Select 监控客户端请求事件, 收到事件后通过 Dispatch 进行分发
- 如果是建立连接请求事件, 则由 Acceptor 通过 Accept 处理连接请求, 然后创建一个 Handler 对象处理连接完成后的后续业务处理
- 如果不是建立连接事件, 则 Reactor 会分发调用连接对应的 Handler 来响应
- Handler 会完成 Read ==》 业务处理 ==》Send 的完整业务流程
单 Reactor 单线程模型只是在代码上进行了组件的区分, 但是整体操作还是单线程, 不能充分利用硬件资源. handler 业务处理部分没有异步
优缺点
服务器端用 一个线程 通过 多路复用 搞定所有的 IO 操作 (包括连接, 读、写等) , 编码简单, 清晰明了, 但是如果客户端连接数量较多, 将无法支撑
优点
- 模型简单, 没有多线程、进程通信、竞争的问题, 全部都在一个线程中完成
缺点
- 性能问题, 只有一个线程, 无法完全发挥多核 CPU 的性能. Handler 在处理某个连接上的业务时, 整个进程无法处理其他连接事件, 很容易导致性能瓶颈
- 可靠性问题, 线程意外终止, 或者进入死循环, 会导致整个系统通信模块不可用, 不能接收和处理外部消息, 造成节点故障
单 Reactor 多线程
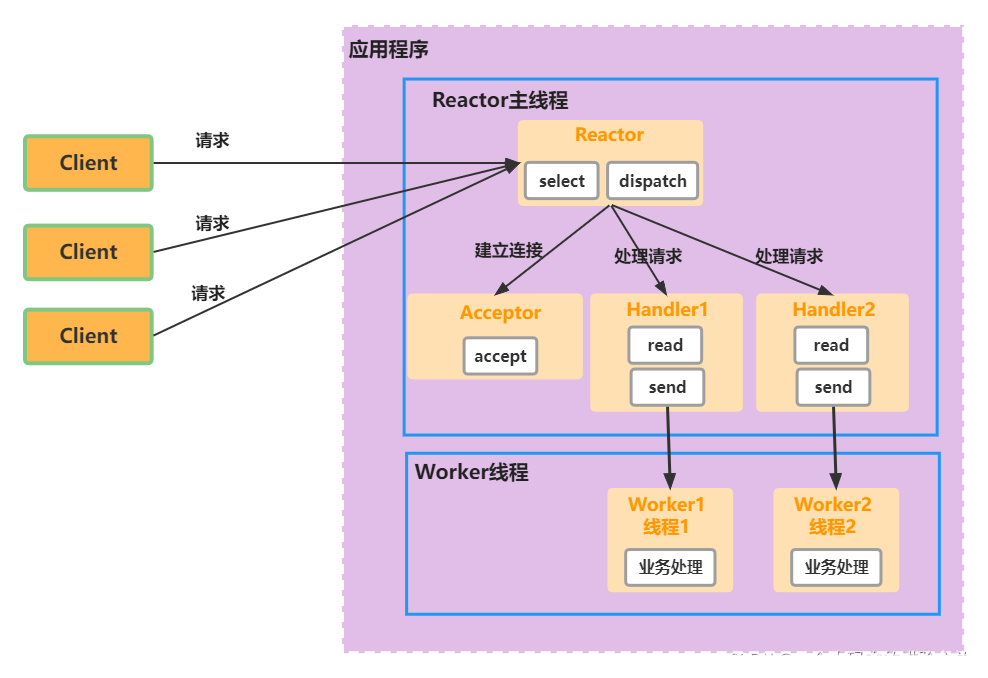
- Reactor 对象通过 select 监控客户端请求事件, 收到事件后, 通过 dispatch 进行分发
- 如果建立连接请求, 则由 Acceptor 通过 accept 处理连接请求, 然后创建一个 Handler 对象处理完成连接后的各种事件
- 如果不是连接请求, 则由 reactor 分发调用连接对应的 handler 来处理
- handler 只负责响应事件, 不做具体的业务处理, 通过 read 读取数据后, 会分发给后面的 worker 线程池的某个线程处理业务
- worker 线程池 会分配独立线程完成真正的业务, 并将结果返回给 handler
- handler 收到响应后, 通过 send 将结果返回给 client
该模型在事件处理器 (Handler) 部分采用了多线程 (线程池)
优缺点
优点
- 可以充分的利用多核 cpu 的处理能力
缺点
- 多线程数据共享和访问比较复杂, reactor 处理所有的事件的监听和响应, 在单线程运行, 在高并发场景容易出现性能瓶颈
主从 Reactor 多线程
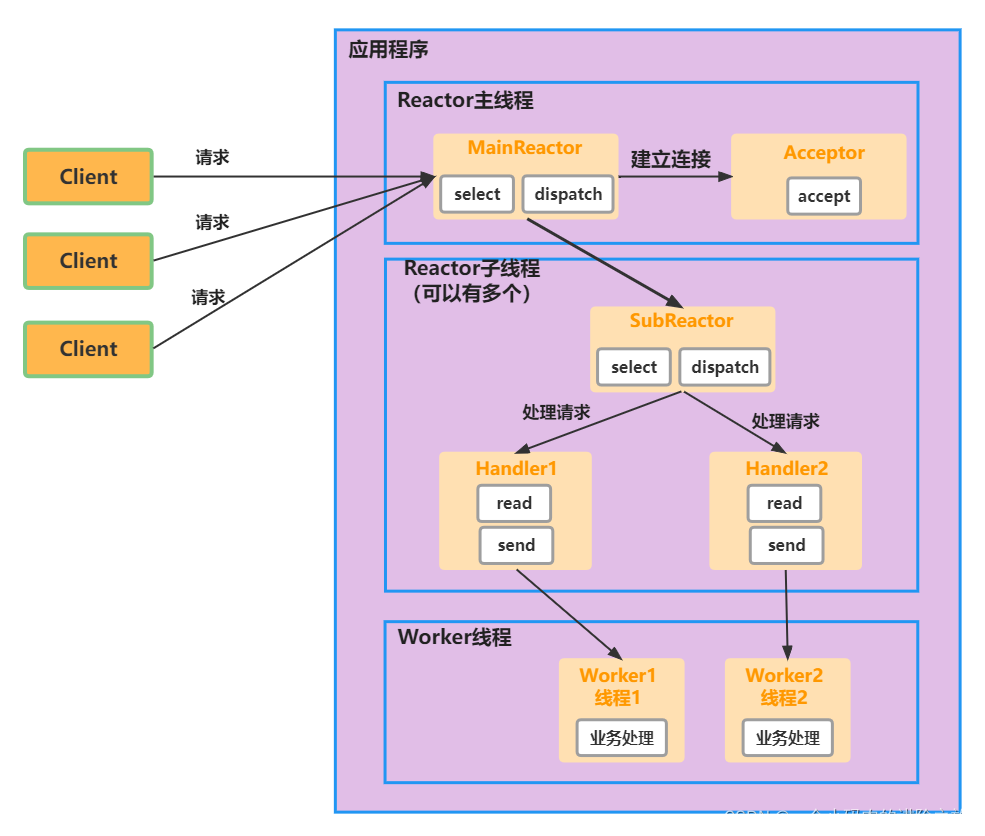
针对单 Reactor 多线程模型中, Reactor 在单线程中运行, 高并发场景下容易成为性能瓶颈, 可以让 Reactor 在多线程中运行
- Reactor 主线程 MainReactor 对象通过 select 监听连接事件, 收到事件后, 通过 Acceptor 处理连接事件
- 当 Acceptor 处理连接事件后, MainReactor 将连接分配给 SubReactor
- SubReactor 将连接加入到连接队列进行监听, 并创建 handler 进行各种事件处理
- 当有新事件发生时, subreactor 就会调用对应的 handler 处理
- handler 通过 read 读取数据, 分发给后面的 worker 线程处理
- worker 线程池分配独立的 worker 线程进行业务处理, 并返回结果
优缺点
这种模型在许多项目中广泛使用, 包括 Nginx 主从 Reactor 多进程模型, Memcached 主从多线程, Netty 主从多线程模型的支持
优点
- 父线程与子线程的数据交互简单职责明确, 父线程只需要接收新连接, 子线程完成后续的业务处理.
- 父线程与子线程的数据交互简单, Reactor 主线程只需要把新连接传给子线程, 子线程无需返回数据.
缺点
- 编程复杂度较高
netty 改进 reactor
Netty 主要基于 主从 Reactor 多线程模型做了一定的 改进, 其中主从 Reactor 多线程模型 有多个 Reactor
简要概述
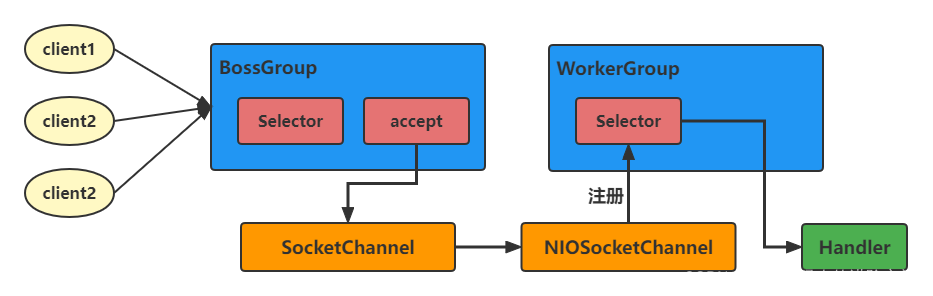
- BossGroup 线程维护 Selector, 只关注 Accecpt;
- 当接收到 Accept 事件, 获取到对应的 SocketChannel, 封装成 NIOScoketChannel 并注册到 Worker 线程(事件循环), 并进行维护;
- 当 Worker 线程监听到 selector 中通道发生自己感兴趣的事件后, 就进行处理(就由 handler), 注意 handler 已经加入到通道
详细说明
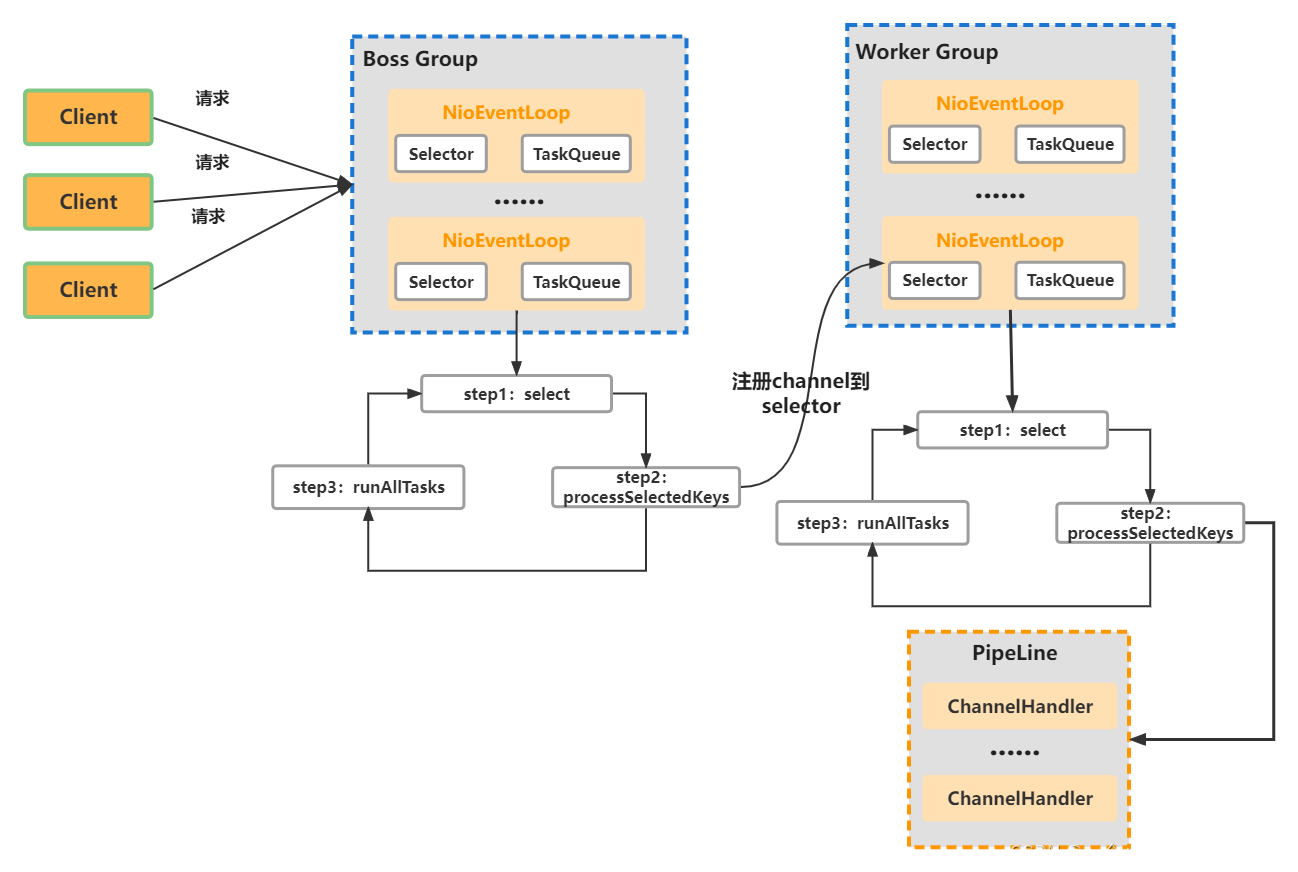
- Netty 抽象出两组线程池: BossGroup 和 WorkerGroup
- BossGroup 专门负责接收客户端的连接
- WorkerGroup 专门负责网络的读写
- BossGroup 和 WorkerGroup 类型都是 NioEventLoopGroup, NioEventLoopGroup 相当于一个 事件循环组, 这个组中 含有多个事件循环 , 每一个事件循环是 NioEventLoop
- NioEventLoop 表示一个不断循环的执行处理任务的线程, 每个 NioEventLoop 都有一个 selector, 用于监听绑定在其上的 socket 的网络通讯
- NioEventLoopGroup 可以有多个线程, 即可以含有多个 NioEventLoop
- 每个 Boss Group 中的 NioEventLoop 循环执行的步骤:
- 轮询 accept 事件
- 处理 accept 事件, 与 client 建立连接, 生成 NioScocketChannel, 并将其注册 Worker Group 上的某个 NIOEventLoop 上的 selector
- 处理任务队列的任务, 即 runAllTasks
- 每个 Worker Group 中的 NioEventLoop 循环执行的步骤:
- 轮询 read/write 事件
- 处理 I/O 事件, 即 read/write 事件, 在对应的 NioScocketChannel 上处理
- 处理任务队列的任务, 即 runAllTasks
- 每个 Worker NIOEventLoop 处理业务时, 会使用 pipeline(管道). pipline 中包含了 channel, 即通过 pipline 可以获取到对应的 channel, 并且 pipline 维护了很多的 handler(处理器)来对我们的数据进行一系列的处理
- handler(处理器) 可以用 Netty 内置的, 也可以自己定义
netty 的 FastThreadLocal
JDK ThreadLocal 基本原理
ThreadLocal 可以理解为线程本地变量, 它是 Java 并发编程中非常重要的一个类. ThreadLocal 为变量在每个线程中都创建了一个副本, 该副本只能被当前线程访问, 多线程之间是隔离的, 变量不能在多线程之间共享. 这样每个线程修改变量副本时, 不会对其他线程产生影响.
接下来我们通过一个例子看下 ThreadLocal 如何使用:
1 | public class ThreadLocalTest { |
在上述示例中, 构造了 THREAD_NAME_LOCAL 和 TRADE_THREAD_LOCAL 两个 ThreadLocal 变量, 分别用于记录当前线程名称和订单交易信息.
通过 set()/get() 方法设置和读取 ThreadLocal 实例. 一起看下示例代码的运行结果:
1 | threadName: thread-0 |
可以看出 thread-1 和 thread-2 虽然操作的是同一个 ThreadLocal 对象, 但是它们取到了不同的线程名称和订单交易信息.
**那么一个线程内如何存在多个 ThreadLocal 对象, 每个 ThreadLocal 对象是如何存储和检索的呢? **
ThreadLocal 实现原理
既然多线程访问 ThreadLocal 变量时都会有自己独立的实例副本, 那么很容易想到的方案就是在 ThreadLocal 中维护一个 Map, 记录线程与实例之间的映射关系. 当新增线程和销毁线程时都需要更新 Map 中的映射关系, 因为会存在多线程并发修改, 所以需要保证 Map 是线程安全的.
那么 JDK 的 ThreadLocal 是这么实现的吗? 答案是 NO. 因为在高并发的场景并发修改 Map 需要加锁, 势必会降低性能.
JDK 为了避免加锁, 采用了相反的设计思路. 以 Thread 入手, 在 Thread 中维护一个 Map, 记录 ThreadLocal 与实例之间的映射关系, 这样在同一个线程内, Map 就不需要加锁了.
从源码中可以发现 Thread 使用的是 ThreadLocal 的内部类 ThreadLocalMap.
ThreadLocalMap 内部实现
ThreadLocalMap 其实与 HashMap 的数据结构类似, 但是 ThreadLocalMap 不具备通用性, 它是为 ThreadLocal 量身定制的.
ThreadLocalMap 是一种使用线性探测法实现的哈希表, 底层采用数组存储数据.
ThreadLocalMap 会初始化一个长度为 16 的 Entry 数组, 每个 Entry 对象用于保存 key-value 键值对. 与 HashMap 不同的是, Entry 的 key 就是 ThreadLocal 对象本身, value 就是用户具体需要存储的值.
ThreadLocal 在新建对象时会初始化一个 threadLocalHashCode 字段, threadLocalHashCode 初始化源码:
1 | public class ThreadLocal<T> { |
由上面源码可知, 每次新建对象, Hash 值就会固定增加 0x61c88647.
为什么取 0x61c88647 这个数呢? 实验证明, 通过 0x61c88647 累加生成的 threadLocalHashCode 与 2 的幂取模, 得到的结果可以较为均匀地分布在长度为 2 的幂大小的数组中.
为了便于理解, 我们采用一组简单的数据模拟 ThreadLocal.set() 的过程是如何解决 Hash 冲突的:
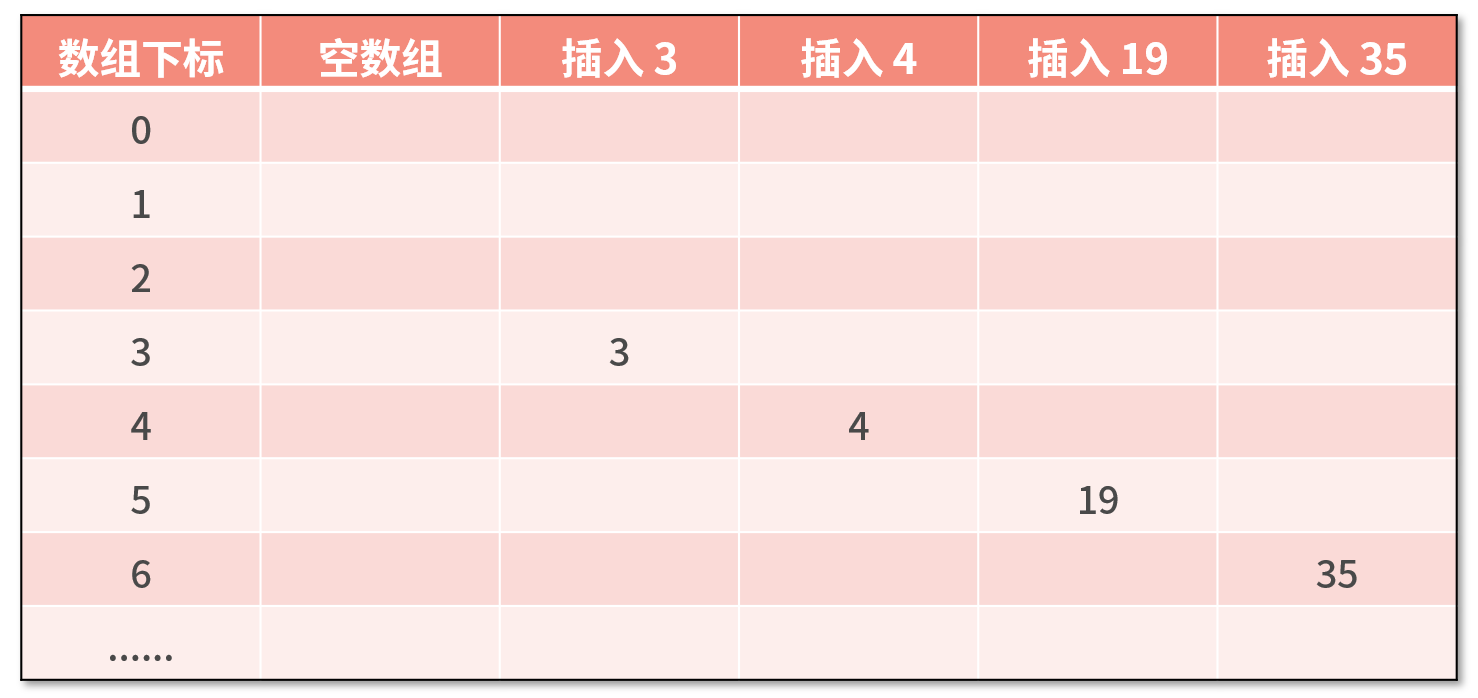
- threadLocalHashCode = 4, threadLocalHashCode & 15 = 4; 此时数据应该放在数组下标为 4 的位置. 下标 4 的位置正好没有数据, 可以存放.
- threadLocalHashCode = 19, threadLocalHashCode & 15 = 4; 但是下标 4 的位置已经有数据了, 如果当前需要添加的 Entry 与下标 4 位置已存在的 Entry 两者的 key 相同, 那么该位置 Entry 的 value 将被覆盖为新的值. 我们假设 key 都是不相同的, 所以此时需要向后移动一位, 下标 5 的位置没有冲突, 可以存放.
- threadLocalHashCode = 35, threadLocalHashCode & 15 = 3; 下标 3 的位置已经有数据, 向后移一位, 下标 4 位置还是有数据, 继续向后查找, 发现下标 6 没有数据, 可以存放.
set() 方法源码:
1 | /** |
ThreadLocal.get() 的过程也是类似的, 也是**根据 threadLocalHashCode 的值定位到数组下标, 然后判断当前位置 Entry 对象与待查询 Entry 对象的 key 是否相同, 如果不同, 继续向下查找. **
由此可见, **ThreadLocal.set()/get() 方法在数据密集时很容易出现 Hash 冲突, 需要 O(n) 时间复杂度解决冲突问题, 效率较低. **
ThreadLocalMap 中 Entry 设计原理
Entry 继承自弱引用类 WeakReference, Entry 的 key 是弱引用, value 是强引用. 在 JVM 垃圾回收时, 只要发现了弱引用的对象, 不管内存是否充足, 都会被回收.
**为什么 Entry 的 key 要设计成弱引用? **
我们试想下, 如果 key 都是强引用, 当 ThreadLocal 不再使用时, 然而 ThreadLocalMap 中还是存在对 ThreadLocal 的强引用, 那么 GC 是无法回收的, 从而造成内存泄漏.
虽然 Entry 的 key 设计成了弱引用, 但是当 ThreadLocal 不再使用被 GC 回收后, ThreadLocalMap 中可能出现 Entry 的 key 为 NULL, 那么 Entry 的 value 一直会强引用数据而得不到释放, 只能等待线程销毁.
**如何避免 ThreadLocalMap 内存泄漏? **
ThreadLocal 已经帮助我们做了一定的保护措施, 在执行 ThreadLocal.set()/get() 方法时, ThreadLocal 会清除 ThreadLocalMap 中 key 为 NULL 的 Entry 对象, 让它还能够被 GC 回收.
除此之外, 编码时当线程中某个 ThreadLocal 对象不再使用时, 立即调用 remove() 方法删除 Entry 对象. 如果是在异常的场景中, 记得在 finally 代码块中进行清理, 保持良好的编码意识.
FastThreadLocal 为什么快
FastThreadLocal 的实现与 ThreadLocal 非常类似, Netty 为 FastThreadLocal 量身打造了 FastThreadLocalThread 和 InternalThreadLocalMap 两个重要的类.
FastThreadLocalThread 是对 Thread 类的一层包装, 每个线程对应一个 InternalThreadLocalMap 实例. 只有 FastThreadLocal 和 FastThreadLocalThread 组合使用时, 才能发挥 FastThreadLocal 的性能优势.
FastThreadLocal 源码定义
1 | public class FastThreadLocal<V> { |
FastThreadLocalThread 源码定义
1 | public class FastThreadLocalThread extends Thread { |
InternalThreadLocalMap 源码定义
可以看出 FastThreadLocalThread 主要扩展了 InternalThreadLocalMap 字段
1 | public final class InternalThreadLocalMap extends UnpaddedInternalThreadLocalMap { |
源码解析
从 InternalThreadLocalMap 内部实现来看, 与 ThreadLocalMap 一样都是采用数组的存储方式.
但是 InternalThreadLocalMap 并没有使用线性探测法来解决 Hash 冲突, 而是在 FastThreadLocal 初始化的时候分配一个数组索引 index, index 的值采用原子类 AtomicInteger 保证顺序递增, 通过调用 InternalThreadLocalMap.nextVariableIndex() 方法获得. 然后在读写数据的时候通过数组下标 index 直接定位到 FastThreadLocal 的位置, 时间复杂度为 O(1). 如果数组下标递增到非常大, 那么数组也会比较大, 所以 FastThreadLocal 是通过空间换时间的思想提升读写性能.
FastThreadLocal 的使用方法几乎和 ThreadLocal 保持一致, 只需要把代码中 Thread、ThreadLocal 替换为 FastThreadLocalThread 和 FastThreadLocal 即可.
FastThreadLocal.set() 源码:
1 | public class FastThreadLocal<V> { |
获取当前线程的 InternalThreadLocalMap 是调用 InternalThreadLocalMap.get() , 逻辑很简单:
- 如果当前线程是 FastThreadLocalThread 类型, 那么直接通过 fastGet() 方法获取 FastThreadLocalThread 的 threadLocalMap 属性即可. 如果此时 InternalThreadLocalMap 不存在, 直接创建一个返回.
- 当前线程是其他类型, 通过 slowGet() 获取 InternalThreadLocalMap, 可以看出 slowThreadLocalMap 是一个 JDK 原生的 ThreadLocal, ThreadLocal 中存放着 InternalThreadLocalMap, 此时获取 InternalThreadLocalMap 就退化成 JDK 原生的 ThreadLocal 获取.
将 InternalThreadLocalMap 中对应数据替换为新的 value 是调用 setKnownNotUnset() :
- setKnownNotUnset() 主要做了两件事:
- 找到数组下标 index 位置, 设置新的 value
- 将 FastThreadLocal 对象保存到待清理的 Set 中
- 从源码中可以知道, 如果数组包含 index 索引, 那么直接找到数组下标 index 位置将新 value 设置进去, 事件复杂度为 O(1); 否则, InternalThreadLocalMap 会自动扩容, 然后再设置 value
- 扩容逻辑类似于 HashMap.tableSizeFor(int cap)
将 FastThreadLocal 对象保存到待清理的 Set 中是调用 addToVariablesToRemove():
- variablesToRemoveIndex 是静态变量, 被初始化为 InternalThreadLocalMap 的第一个 index (目前为 0), 所以 InternalThreadLocalMap 的 value 数据是从下标为 1 的位置开始存储
- 由源码可以看出 InternalThreadLocalMap index 为 0 的位置是 FastThreadLocal 类型的 Set 集合
FastThreadLocal.set() 中 remove() 语句执行过程:
- 调用 InternalThreadLocalMap.getIfSet() 获取当前 InternalThreadLocalMap
- InternalThreadLocalMap 将数组 index 位置的元素覆盖为缺省对象 UNSET. 然后清理数组下标 0 位置的 Set 集合中当前的 FastThreadLocal 对象
- 最后 onRemoval() 方法是 Netty 留的一处扩展, 并没有实现, 用户需要在删除的时候做一些后置操作, 可以继承 FastThreadLocal 实现该方法
netty 时间轮
时间轮是任务调度算法的实现, 与其他专门的任务调度框架不同, Netty 以单个线程为单位来调度任务, 比如 EventLoop, 因此调度的任务数量有限. Netty 借助优先级队列来实现时间轮, runAllTask 发起对定时任务的调度, 主要逻辑是从 scheduledTaskQueue 移动到 taskQueue, 根据优先级队列弹出哪些过期的事件. 当定时任务鉴定完毕并移除完毕后, 就开始执行, 这个动作是在 runAllTask 方法中完成的, 每执行 64 个任务就会检测一次是否达到 runAllTask 的执行时间上限.
时间轮算法
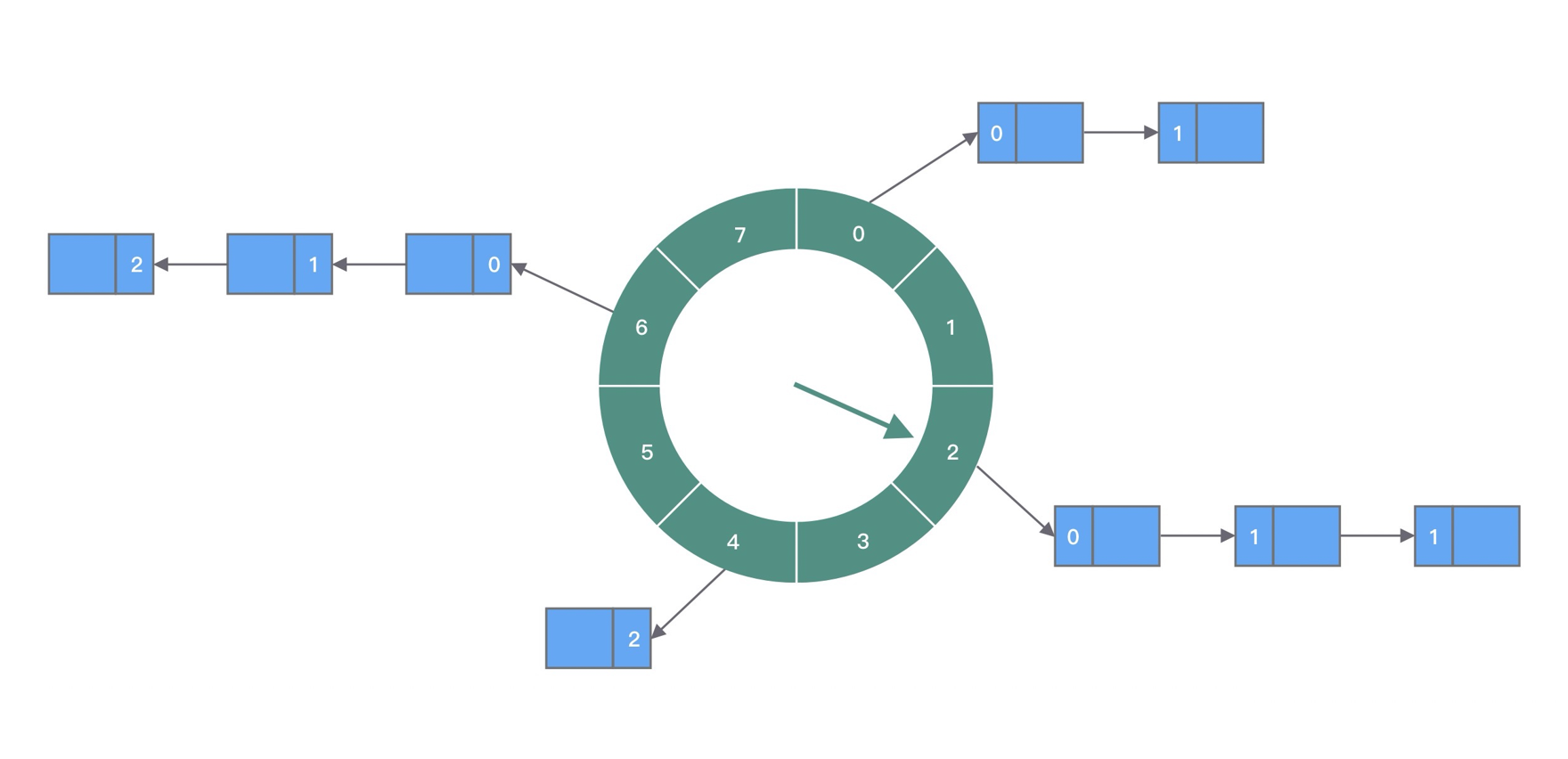
时间轮算法的设计思想就来源于钟表. 如下图所示, 时间轮可以理解为一种环形结构, 像钟表一样被分为多个 slot 槽位. 每个 slot 代表一个时间段, 每个 slot 中可以存放多个任务, 使用的是链表结构保存该时间段到期的所有任务. 时间轮通过一个时针随着时间一个个 slot 转动, 并执行 slot 中的所有到期任务.
结合上图分析时间轮的任务添加与执行逻辑:
- 假设时间轮被划分为 8 个 slot, 每个 slot 代表 1s, 当前时针指向 2
- 假如现在需要调度一个 3s 后执行的任务, 应该加入 2+3=5 的 slot 中; 如果需要调度一个 12s 以后的任务, 需要等待时针完整走完一圈 round 零 4 个 slot, 需要放入第 (2+12)%8=6 个 slot
- 当时针走到第 6 个 slot 时, 怎么区分每个任务是否需要立即执行, 还是需要等待下一圈 round, 甚至更久时间之后执行呢?
- 需要把 round 信息保存在任务中. 例如图中第 6 个 slot 的链表中包含 3 个任务, 第一个任务 round=0, 需要立即执行; 第二个任务 round=1, 需要等待 18=8s 后执行; 第三个任务 round=2, 需要等待 28=8s 后执行.
- 当时针转动到对应 slot 时, 只执行 round=0 的任务, slot 中其余任务的 round 应当减 1, 等待下一个 round 之后执行
netty HashedWheelTimer 源码解析
HashedWheelTimer 源码定义
1 | public class HashedWheelTimer implements Timer { |
HashedWheelTimer 实现了接口 io.netty.util.Timer
Timer 接口提供了两个方法, 分别是创建任务 newTimeout() 和停止所有未执行任务 stop(). 从方法的定义可以看出, Timer 可以认为是上层的时间轮调度器, 通过 newTimeout() 方法可以提交一个任务 TimerTask, 并返回一个 Timeout.
Timeout 持有 Timer 和 TimerTask 的引用, 而且通过 Timeout 接口可以执行取消任务的操作
HashedWheelTimer 示例
1 |
|
代码运行结果如下:
1 | timeout2: Wed Apr 26 20:21:22 CST 2023 |
示例中我们通过 newTimeout() 启动了三个 TimerTask:
- timeout1 由于被取消了, 所以并没有执行
- timeout2 和 timeout3 分别应该在 1s 和 3s 后执行. 然而从结果输出看并不是, timeout2 和 timeout3 的打印时间相差了 5s, 这是由于 timeout2 阻塞了 5s 造成的.
由此可以看出, 时间轮中的任务执行是串行的, 当一个任务执行的时间过长, 会影响后续任务的调度和执行, 很可能产生任务堆积的情况.
参考资料
- Netty 系列——NIO
- 16 IO 加速: 与众不同的 Netty 零拷贝技术
- Netty 是如何检测资源泄漏的?
- 12 他山之石: 高性能内存分配器 jemalloc 基本原理
- jemalloc-4.2.1-readcode
- Netty 入门 3 之—-Decoder 和 Encoder
- Netty(七) Netty 编解码与 TCP 粘包,拆包
- tcp 粘包与 udp 丢包的原因
- 深入剖析 Linux IO 原理和几种零拷贝机制的实现
- 20 技巧篇: Netty 的 FastThreadLocal 究竟比 ThreadLocal 快在哪儿?
- 彻底搞懂 Reactor 模型和 Proactor 模型
- 【Netty】模型篇一: Netty 线程模型架构 & 工作原理 解读
- 21 技巧篇: 延迟任务处理神器之时间轮 HashedWheelTimer